Remarque
Cette commande est disponible avec le Module d'analyse prédictive. Cliquez ici pour plus d'informations sur l'activation du module.
Un modèle Random Forests® est une approche pour résoudre les problèmes de classification et de régression. L’approche est à la fois plus précise et plus robuste aux variations des variables de prédiction qu'un seul arbre de classification ou de régression. On peut décrire généralement la procédure comme une construction d'un arbre unique à partir d'un échantillon bootstrap par Minitab Statistical Software. Minitab sélectionne aléatoirement un plus petit nombre de prédicteurs sur le nombre total de prédicteurs pour évaluer le meilleur séparateur à chaque nœud. Minitab répète ce processus pour développer de nombreux arbres. Dans le cas de la régression, la prédiction du modèle est la moyenne des prédictions de tous les arbres individuels.
Pour construire un arbre de régression, l’algorithme utilise le critère des moindres carrés pour mesurer l'impureté des nœuds. Pour l’application de bureau, chaque arborescence s’agrandit jusqu’à ce qu’un nœud soit impossible à fractionner ou qu’un nœud atteigne le nombre minimum de cas pour diviser un nœud interne. Le nombre minimum de cas est une option pour l’analyse. Pour l’application Web, l’analyse ajoute la contrainte que chaque arbre a une limite de 4 000 nœuds de terminal. Pour plus de détails sur la construction d'un arbre de régression, passez à Méthodes de partition des nœuds dans Régression CART®. Vous trouverez ci-dessous des détails spécifiques de l'algorithme Random Forests®.
Échantillons bootstrap
Pour construire chaque arbre, l'algorithme sélectionne un échantillon aléatoire avec remplacement (échantillon bootstrap) dans l'ensemble de données complet. Habituellement, chaque échantillon bootstrap est différent et peut contenir un nombre différent de lignes uniques de l'ensemble de données d’origine. Si vous n'utilisez que la validation out-of-bag, la taille par défaut de l'échantillon bootstrap est la taille de l'ensemble de données d’origine. Si vous divisez l’échantillon en un ensemble d'apprentissage et un ensemble de test, la taille par défaut de l'échantillon bootstrap est la même que la taille de l'ensemble d'apprentissage. Dans les deux cas, vous avez la possibilité de spécifier une taille de l'échantillon bootstrap plus petite que la taille par défaut. En moyenne, un échantillon bootstrap contient environ 2/3 des lignes de données. Les lignes uniques de données qui ne sont pas dans l'échantillon bootstrap sont les données out-of-bag pour validation.
Sélection aléatoire des prédicteurs
À chaque nœud de l'arbre, l'algorithme sélectionne aléatoirement un sous-ensemble du nombre total de prédicteurs, 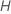 , à évaluer en tant que séparateurs. Par défaut, l'algorithme choisit
, à évaluer en tant que séparateurs. Par défaut, l'algorithme choisit 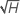 prédicteurs à évaluer à chaque nœud. Vous avez la possibilité de choisir un nombre différent de prédicteurs à évaluer, de 1 à
prédicteurs à évaluer à chaque nœud. Vous avez la possibilité de choisir un nombre différent de prédicteurs à évaluer, de 1 à 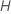 . Si vous choisissez
. Si vous choisissez 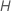 prédicteurs, l'algorithme évalue chaque prédicteur à chaque nœud, ce qui produit une analyse appelée "forêt bootstrap".
prédicteurs, l'algorithme évalue chaque prédicteur à chaque nœud, ce qui produit une analyse appelée "forêt bootstrap".
Dans une analyse qui utilise un sous-ensemble de prédicteurs à chaque nœud, les prédicteurs évalués sont généralement différents à chaque nœud. L'évaluation de différents prédicteurs rend les arbres de la forêt moins corrélés entre eux. Les arbres moins corrélés créent un effet d'apprentissage lent de sorte que les prédictions s'améliorent à mesure que vous construisez plus d'arbres.
Validation avec les données out-of-bag
Les lignes uniques de données qui ne font pas partie du processus de construction d'arbres pour un arbre donné sont les données out-of-bag. Les calculs pour les mesures des performances du modèle utilisent les données out-of-bag. Pour plus d'informations, reportez-vous à Méthodes et formules pour le récapitulatif du modèle dans Régression Random Forests®.
Pour un arbre donné dans la forêt, une prédiction pour une ligne dans les données out-of-bag est faite à partir de l'arbre unique. La prédiction d'une ligne de données out-of-bag est la moyenne des prédictions des arbres individuels.
Prévision d'une ligne dans l'ensemble d'apprentissage
Chaque arbre de la forêt fait une prédiction individuelle pour chaque ligne de l'ensemble d'apprentissage. La valeur prévue pour une ligne dans l'ensemble d'apprentissage est la moyenne des valeurs prévues de tous les arbres de la forêt.