Remarque
Cette commande est disponible avec le Module d'analyse prédictive. Cliquez ici pour plus d'informations sur l'activation du module.
Sur ce thème
Out-of-bag
Pour un arbre donné dans la forêt, un vote de classe pour une ligne dans les données out-of-bag est la classe prévue pour la ligne d'après l'arbre unique. La classe prévue pour une ligne dans les données out-of-bag est la classe de vote le plus élevé sur tous les arbres de la forêt. La probabilité de classe prévue pour une ligne dans les données out-of-bag est le rapport entre le nombre de votes pour la classe et le total des votes pour la ligne.
Pour la courbe des données out-of-bag, chaque point du graphique représente une probabilité distincte de classe prévue. La probabilité d’événement la plus élevée est le premier point sur la courbe et apparaît le plus à gauche. Les autres probabilités sont classées par ordre décroissant.
Les points de la courbe de lift non cumulé ne suivent pas le calcul des points sur le graphique de courbe ROC. Au lieu de cela, la coordonnée y de la courbe de lift non cumulé est (taux positif vrai non cumulé en pourcentage / % de la population à la coordonnée x). Le calcul du taux positif réel est exactement le même que pour le graphique de courbe ROC.
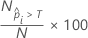
où 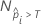 est le nombre de lignes où la probabilité ajustée est supérieure au seuil et N est le nombre total de lignes. Pour plus de détails sur les seuil, reportez-vous à Méthodes et formules pour la courbe d'efficacité du récepteur (ROC) pour Classification Random Forests®.
est le nombre de lignes où la probabilité ajustée est supérieure au seuil et N est le nombre total de lignes. Pour plus de détails sur les seuil, reportez-vous à Méthodes et formules pour la courbe d'efficacité du récepteur (ROC) pour Classification Random Forests®.
Ensemble de test distinct
Procédez comme pour le cas d'un ensemble d'apprentissage, mais calculez les probabilités d'événements à partir des cas pour l'ensemble de test.