Pour déterminer l'ajustement du modèle aux données, étudiez les statistiques dans le tableau Récapitulatif du modèle.
Nombre total de prédicteurs
Nombre total de prédicteurs disponibles pour le modèle. Il s'agit de la somme des prédicteurs continus et de catégorie que vous spécifiez.
Prédicteurs importants
Nombre de prédicteurs importants dans le modèle. Les prédicteurs importants sont les variables qui ont au moins 1 fonction de base dans le modèle.
Interprétation
Vous pouvez utiliser le diagramme d'importance relative des variables pour afficher l'ordre d'importance relative des variables. Par exemple, supposons que 10 des 20 prédicteurs aient des fonctions de base dans le modèle, le diagramme d’importance relative des variables affiche les variables dans l’ordre d’importance.
Nombre maximal de fonctions de base
Nombre de fonctions de base que l’algorithme construit pour rechercher le modèle optimal.
Interprétation
Par défaut, Minitab Statistical Software définit le nombre maximal de fonctions de base sur 30. Considérez une valeur plus grande lorsque 30 fonctions de base semblent trop petites pour les données. Par exemple, considérez une valeur plus élevée lorsque vous pensez que plus de 30 prédicteurs sont importants.
Nombre optimal de fonctions de base
Nombre de fonctions de base dans le modèle optimal.
Interprétation
Une fois que l’analyse a estimé le modèle avec le nombre maximal de fonctions de base, l’analyse utilise une procédure d’élimination vers l’arrière pour supprimer les fonctions de base du modèle. Une par une, l’analyse supprime la fonction de base qui contribue le moins à l’ajustement du modèle. À chaque étape, l’analyse calcule la valeur du critère d’optimalité pour l’analyse, soit R-carré, soit écart absolu moyen. Une fois la procédure d’élimination terminée, le nombre optimal de fonctions de base est le nombre de la procédure d’élimination qui produit la valeur optimale du critère.
R carré
Le R2 est le pourcentage de variation dans la réponse que le modèle explique. Les valeurs aberrantes ont un plus grand effet sur le R2 que sur le MAD et le MAPE.
Lorsque vous utilisez une méthode de validation, le tableau inclut une statistique R2 pour l'ensemble de données d'apprentissage et une statistique R2 pour l'ensemble de données de test. Lorsque la méthode de validation est la validation croisée sur K ensembles, l'ensemble de données de test est chaque partition lorsque la construction du modèle exclut cette partition. La statistique R2 de test est généralement une meilleure mesure de la qualité du modèle avec de nouvelles données.
Interprétation
Utilisez le R2 pour déterminer la qualité d'ajustement offert par le modèle. Plus la valeur de R2 est élevée, plus l'ajustement offert par le modèle est bon. R2 est toujours compris entre 0% et 100%.
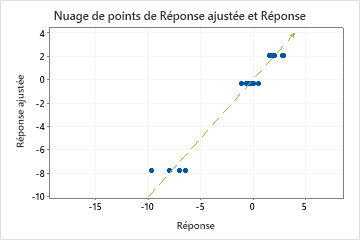
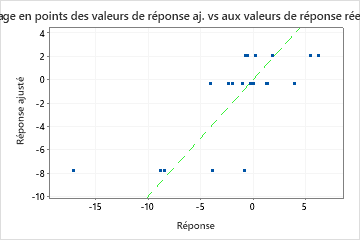
Un R2 de test nettement inférieur au R2 d'apprentissage indique que le modèle peut ne pas prédire les valeurs de réponse pour les nouveaux cas aussi bien qu'il ajuste l'ensemble de données actuel.
Racine de l'erreur quadratique moyenne (RMSE)
La racine de l'erreur quadratique moyenne (RMSE) mesure l'exactitude du modèle. Les valeurs aberrantes ont un plus grand effet sur la RMSE que sur le MAD et le MAPE.
Lorsque vous utilisez une méthode de validation, le tableau inclut une statistique RMSE pour l'ensemble de données d'apprentissage et une statistique RMSE pour l'ensemble de données de test. Lorsque la méthode de validation est la validation croisée sur K ensembles, l'ensemble de données de test est chaque partition lorsque la construction du modèle exclut cette partition. La statistique RMSE de test est généralement une meilleure mesure de la qualité du modèle avec de nouvelles données.
Interprétation
Utilisez cette statistique pour comparer les valeurs ajustées de différents modèles. Des valeurs plus petites indiquent un meilleur ajustement. Une RMSE de test nettement inférieure à la RMSE d'apprentissage indique que le modèle peut ne pas prédire les valeurs de réponse pour les nouveaux cas aussi bien qu'il ajuste l'ensemble de données actuel.
Erreur quadratique moyenne (MSE)
L'erreur quadratique moyenne (MSE) mesure l'exactitude du modèle. Les valeurs aberrantes ont un plus grand effet sur la MSE que sur le MAD et le MAPE.
Lorsque vous utilisez une méthode de validation, le tableau inclut une statistique MSE pour l'ensemble de données d'apprentissage et une statistique MSE pour l'ensemble de données de test. Lorsque la méthode de validation est la validation croisée sur K ensembles, l'ensemble de données de test est chaque partition lorsque la construction du modèle exclut cette partition. La statistique MSE de test est généralement une meilleure mesure de la qualité du modèle avec de nouvelles données.
Interprétation
Utilisez cette statistique pour comparer les valeurs ajustées de différents modèles. Des valeurs plus petites indiquent un meilleur ajustement. Un MSE de test nettement inférieur au MSE d'apprentissage indique que le modèle peut ne pas prédire les valeurs de réponse pour les nouveaux cas aussi bien qu'il ajuste l'ensemble de données actuel.
Écart absolu moyen (MAD)
L'écart absolu moyen (MAD) exprime l'exactitude dans les mêmes unités que les données, ce qui permet de conceptualiser la quantité d'erreurs. Les valeurs aberrantes ont moins d'effet sur le MAD que sur le R2, la RMSE et la MSE.
Lorsque vous utilisez une méthode de validation, le tableau inclut une statistique MAD pour l'ensemble de données d'apprentissage et une statistique MAD pour l'ensemble de données de test. Lorsque la méthode de validation est la validation croisée sur K ensembles, l'ensemble de données de test est chaque partition lorsque la construction du modèle exclut cette partition. La statistique MAD de test est généralement une meilleure mesure de la qualité du modèle avec de nouvelles données.
Interprétation
Utilisez cette statistique pour comparer les valeurs ajustées de différents modèles. Des valeurs plus petites indiquent un meilleur ajustement. Un MAD de test nettement inférieur au MAD d'apprentissage indique que le modèle peut ne pas prédire les valeurs de réponse pour les nouveaux cas aussi bien qu'il ajuste l'ensemble de données actuel.