Pour le pourcentage de statistiques d'erreur, la valeur dépend du pourcentage des valeurs résiduelles les plus grandes dans le calcul. Dans les formules suivantes, les calculs supposent que les valeurs résiduelles sont classées par valeur absolue, de sorte que i = 1 représente la valeur résiduelle avec la plus grande valeur absolue et i = N représente la valeur résiduelle avec la plus petite valeur absolue.
Lorsque vous utilisez la validation croisée sur K partitions, les statistiques d'apprentissage incluent les valeurs ajustées de l'arbre final pour l'ensemble complet de données. Les statistiques de test utilisent des valeurs ajustées du processus de validation qui peuvent avoir des arbres différents pour chaque partition.
Lorsque vous utilisez un ensemble de données de test pour validation, les statistiques de test utilisent des valeurs ajustées pour l'ensemble de données de test uniquement.
% MSE
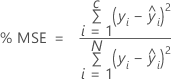
% MAD
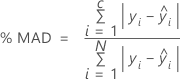
% MAPE
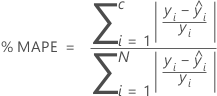
Notation
| Terme | Description |
|---|---|
| c | nombre des résidus les plus importants pour le pourcentage |
| yi | valeur de réponse observée i e |
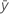 | réponse moyenne |
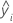 | réponse équipée i e |
| N | nombre d’enregistrements |