Nombre total de prédicteurs
Nombre total de prédicteurs disponibles pour l'arbre. Il s'agit de la somme des prédicteurs continus et de catégorie que vous spécifiez.
Prédicteurs importants
Nombre de prédicteurs importants dans l'arbre. Les prédicteurs importants sont les variables utilisées comme séparateurs principaux ou de substitution.
Interprétation
Vous pouvez utiliser le diagramme d'importance relative des variables pour afficher l'ordre d'importance relative des variables. Par exemple, supposons que 10 des 20 prédicteurs soient importants dans l'arbre, le diagramme d'importance relative des variables affiche les variables dans l'ordre d'importance.
Nombre de nœuds terminaux
Un nœud terminal est un nœud final qui ne peut pas être divisé davantage.
Interprétation
Vous pouvez utiliser les informations des nœuds terminaux pour faire des prévisions.
Taille minimale des nœuds terminaux
La taille minimale des nœuds terminaux correspond au nœud terminal avec le plus petit nombre de cas.
Interprétation
Par défaut, Minitab définit le nombre minimal de cas autorisés pour un nœud terminal à 3 ; cependant, la taille minimale des nœuds terminaux d'un arbre peut être plus grande que le nombre minimal autorisé par l'analyse. Vous pouvez modifier cette valeur de seuil dans la sous-boîte de dialogue Options.
R carré
Le R2 est le pourcentage de variation dans la réponse que le modèle explique. Les valeurs aberrantes ont un plus grand effet sur le R2 que sur le MAD et le MAPE.
Lorsque vous utilisez une méthode de validation, le tableau inclut une statistique R2 pour l'ensemble de données d'apprentissage et une statistique R2 pour l'ensemble de données de test. Lorsque la méthode de validation est la validation croisée sur K ensembles, l'ensemble de données de test est chaque partition lorsque la construction de l'arbre exclut cette partition. La statistique R2 de test est généralement une meilleure mesure de la qualité du modèle avec de nouvelles données.
Interprétation
Utilisez le R2 pour déterminer la qualité d'ajustement offert par le modèle. Plus la valeur de R2 est élevée, plus l'ajustement offert par le modèle est bon. Le R2 se situe toujours entre 0 % et 100 %.
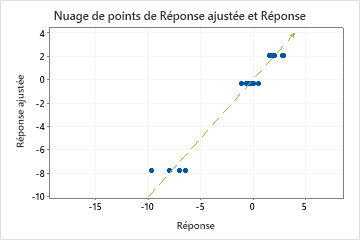
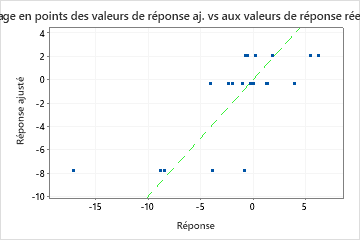
Un R2 de test nettement inférieur au R2 d'apprentissage indique que l'arbre peut ne pas prédire les valeurs de réponse pour les nouveaux cas aussi bien qu'il ajuste l'ensemble de données actuel.
Racine de l'erreur quadratique moyenne (RMSE)
La racine de l'erreur quadratique moyenne (RMSE) mesure l'exactitude de l'arbre. Les valeurs aberrantes ont un plus grand effet sur la RMSE que sur le MAD et le MAPE.
Lorsque vous utilisez une méthode de validation, le tableau inclut une statistique RMSE pour l'ensemble de données d'apprentissage et une statistique RMSE pour l'ensemble de données de test. Lorsque la méthode de validation est la validation croisée sur K ensembles, l'ensemble de données de test est chaque partition lorsque la construction de l'arbre exclut cette partition. La statistique RMSE de test est généralement une meilleure mesure de la qualité du modèle avec de nouvelles données.
Interprétation
Utilisez cette statistique pour comparer les valeurs ajustées de différents arbres. Des valeurs plus petites indiquent un meilleur ajustement. Une RMSE de test nettement plus élevé à la RMSE d'apprentissage indique que l'arbre peut ne pas prédire les valeurs de réponse pour les nouveaux cas aussi bien qu'il ajuste l'ensemble de données actuel.
Erreur quadratique moyenne (MSE)
L'erreur quadratique moyenne (MSE) mesure l'exactitude de l'arbre. Les valeurs aberrantes ont un plus grand effet sur la MSE que sur le MAD et le MAPE.
Lorsque vous utilisez une méthode de validation, le tableau inclut une statistique MSE pour l'ensemble de données d'apprentissage et une statistique MSE pour l'ensemble de données de test. Lorsque la méthode de validation est la validation croisée sur K ensembles, l'ensemble de données de test est chaque partition lorsque la construction de l'arbre exclut cette partition. La statistique MSE de test est généralement une meilleure mesure de la qualité du modèle avec de nouvelles données.
Interprétation
Utilisez cette statistique pour comparer les valeurs ajustées de différents arbres. Des valeurs plus petites indiquent un meilleur ajustement. Un MSE de test nettement plus élevé au MSE d'apprentissage indique que l'arbre peut ne pas prédire les valeurs de réponse pour les nouveaux cas aussi bien qu'il ajuste l'ensemble de données actuel.
Écart absolu moyen (MAD)
L'écart absolu moyen (MAD) exprime l'exactitude dans les mêmes unités que les données, ce qui permet de conceptualiser la quantité d'erreurs. Les valeurs aberrantes ont moins d'effet sur le MAD que sur le R2, la RMSE et la MSE.
Lorsque vous utilisez une méthode de validation, le tableau inclut une statistique MAD pour l'ensemble de données d'apprentissage et une statistique MAD pour l'ensemble de données de test. Lorsque la méthode de validation est la validation croisée sur K ensembles, l'ensemble de données de test est chaque partition lorsque la construction de l'arbre exclut cette partition. La statistique MAD de test est généralement une meilleure mesure de la qualité du modèle avec de nouvelles données.
Interprétation
Utilisez cette statistique pour comparer les valeurs ajustées de différents arbres. Des valeurs plus petites indiquent un meilleur ajustement. Un MAD de test nettement plus élevé au MAD d'apprentissage indique que l'arbre peut ne pas prédire les valeurs de réponse pour les nouveaux cas aussi bien qu'il ajuste l'ensemble de données actuel.
Pourcentage d'erreur absolue moyen (MAPE)
Le pourcentage d'erreur absolue moyen (MAPE) exprime l'exactitude en pourcentage d'erreur. Étant donné que le MAPE est un pourcentage, il peut être plus facile à comprendre que les autres statistiques de mesure de l'exactitude. Par exemple, si le MAPE est de 0,05 en moyenne, le rapport moyen entre l'erreur ajustée et la valeur réelle est de 5 % dans tous les cas. Les valeurs aberrantes ont moins d'effet sur le MAPE que sur le R2, la RMSE et la MSE.
Cependant, parfois, vous pouvez voir une valeur de MAPE très grande, même si l'arbre semble bien ajuster les données. Examinez le diagramme de la valeur de réponse ajustée par rapport à la valeur de réponse réelle pour voir si les valeurs de données sont proches de 0. Étant donné que le MAPE divise l'erreur absolue par les données réelles, les valeurs proches de 0 peuvent grandement augmenter le MAPE.
Lorsque vous utilisez une méthode de validation, le tableau inclut une statistique MAPE pour l'ensemble de données d'apprentissage et une statistique MAPE pour l'ensemble de données de test. Lorsque la méthode de validation est la validation croisée sur K ensembles, l'ensemble de données de test est chaque partition lorsque la construction de l'arbre exclut cette partition. La statistique MAPE de test est généralement une meilleure mesure de la qualité du modèle avec de nouvelles données.
Interprétation
Utilisez cette statistique pour comparer les valeurs ajustées de différents arbres. Des valeurs plus petites indiquent un meilleur ajustement. Un MAPE de test nettement plus élevé au MAPE d'apprentissage indique que l'arbre peut ne pas prédire les valeurs de réponse pour les nouveaux cas aussi bien qu'il ajuste l'ensemble de données actuel.