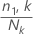La procédure utilisée pour les points de la courbe ROC dépend de la méthode de validation. Pour une variable de réponse multinomiale, Minitab affiche plusieurs courbes qui traitent chaque classe une à une comme l’événement.
Ensemble de données d’apprentissage ou aucune validation
Chaque point de la courbe d’un ensemble de données d’apprentissage représente un nœud terminal de l’arbre. Le nœud terminal avec la probabilité d’événement la plus élevée est le premier point sur la courbe et apparaît le plus à gauche. Les autres nœuds terminaux sont dans l’ordre de probabilité d’événement décroissante.
Utilisez le procédé suivant pour trouver les coordonnées X et Y sur la courbe.
Calculez la probabilité d’événement de chaque nœud terminal :
où
N1,k1,k est le nombre d'événements dans le ke nœud
Nk est le nombre de cas dans le ke nœud
Classez les nœuds terminaux par probabilité d'événement, de la plus élevée à la plus faible.
Utilisez chaque probabilité d’événement comme seuil. Pour un seuil spécifique, les cas dont la probabilité d'événement est estimée supérieure ou égale au seuil ont une classe prévue de 1, contre 0 dans les autres cas. Vous pouvez ensuite créer un tableau 2 x 2 pour tous les cas, en indiquant les classes observées dans les lignes et les classes prédites dans les colonnes pour calculer le taux de faux positifs et le taux de vrais positifs de chaque nœud terminal. Les taux de faux positifs sont les coordonnées X de la courbe et les taux de vrais positifs les coordonnées Y.
Supposons, par exemple, que le tableau suivant résume les valeurs d'un arbre avec 4 nœuds terminaux :
A : Nœud terminal
B : Nombre d'événements
C : Nombre de non-événements
D : Nombre de cas
E : Seuil (B/D)
4
18
12
30
0,60
1
25
42
67
0,37
3
12
44
56
0,21
2
4
32
36
0,11
Totaux
59
130
189
Les 4 tableaux suivants contiennent leurs taux de faux positifs et de vrais positifs respectifs avec 2 chiffres après la virgule :
Suivez les mêmes étapes que pour la procédure de l’ensemble de données d'apprentissage, mais calculez la probabilité d’événement à partir des cas pour l’ensemble de données de test.
Test avec validation croisée sur K partitions
La procédure de définition des coordonnées X et Y sur la courbe ROC avec validation croisée sur K partitions comporte une étape supplémentaire. Cette étape crée de nombreuses probabilités d’événement distinctes. Supposons, par exemple, que l’arborescence contienne 4 nœuds terminaux. Nous avons une validation croisée de 10 partitions. Vous utilisez ensuite une portion de 9/10 des données pour la ie partition, afin d'estimer les probabilités d'événements pour les cas de la partition i. Lorsque ce procédé se répète pour chaque partition, le nombre maximal de probabilités d'événements distinctes est de 4 * 10 = 40. Après cela, triez toutes les probabilités d’événement distinctes dans l’ordre décroissant. Utilisez les probabilités d’événement pour chacune des valeurs seuils pour affecter les classes prévues aux cas dans tout l’ensemble de données. Après cette étape, appliquez l’étape 3 jusqu’à la dernière étape de la procédure d’ensemble de données d'apprentissage pour trouver les coordonnées X et Y.