Un arbre de classification résulte d’un partitionnement récursif binaire de l’ensemble de données d’apprentissage d’origine. Tout nœud parent (sous-ensemble de données d’apprentissage) dans un arbre peut être divisé en deux nœuds enfants qui s’excluent mutuellement d’un nombre limité de façons, en fonction des valeurs réelles des données recueillies dans le nœud.
La procédure de partition traite les variables de prédiction comme étant continues ou de catégorie. Pour une variable continue X et une valeur c, la division est définie par l’envoi de toutes les données avec des valeurs de X inférieures ou égales à c au nœud gauche, et de toutes les données restantes au nœud droit. CART utilise toujours la moyenne de deux valeurs adjacentes afin de calculer c. Une variable continue avec N valeurs distinctes génère jusqu’à N-1 divisions potentielles du nœud parent (le nombre réel sera plus petit lorsque des limites sur la taille minimale autorisée du nœud sont imposées).
Par exemple, un prédicteur continu comprend les valeurs 55, 66 et 75. Il est possible de diviser cette variable en envoyant toutes les valeurs inférieures ou égales à (55+66)/2 = 60,5 à un nœud enfant et toutes les valeurs supérieures à 60,5 à l’autre nœud enfant. Les cas avec la valeur de prédiction 55 sont envoyés à un nœud et les cas avec les valeurs 66 et 75 sont envoyés à l’autre nœud. Il est également possible de diviser cette variable de prédiction en envoyant toutes les valeurs inférieures ou égales à 70,5 à un nœud enfant et toutes les valeurs supérieures à 70,5 à l’autre nœud. Les cas avec les valeurs 55 et 66 sont envoyés à un nœud et les cas avec la valeur 75 sont envoyés à l’autre nœud.
Pour une variable de catégorie X avec des valeurs distinctes {c1, c2, …, ck}, une division est définie comme un sous-ensemble de niveaux qui sont envoyés au nœud enfant gauche. Une variable de catégorie avec K niveaux génère jusqu’à 2K-1–1 divisions.
| Nœud enfant gauche | Nœud enfant droit |
|---|---|
| Rouge, Bleu | Jaune |
| Rouge, Jaune | Bleu |
| Bleu, Jaune | Rouge |
Dans les arbres de classification, la cible est multinomiale avec K classes distinctes. L’objectif principal de l’arbre est de trouver un moyen de séparer les différentes classes cibles en nœuds individuels de la manière la plus pure possible. Le nombre de nœuds terminaux qui en résulte n’a pas besoin d’être K. Plusieurs nœuds terminaux peuvent être utilisés pour représenter une classe cible spécifique. Un utilisateur peut spécifier les probabilités antérieures pour les classes cibles et ces probabilités seront comptabilisées par CART pendant le processus de croissance des arbres.
Dans les sections suivantes, Minitab utilise les définitions suivantes pour une variable de réponse binaire :
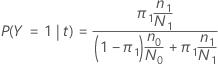
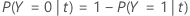
Dans les sections suivantes, Minitab utilise les définitions suivantes pour une variable de réponse multinomiale :
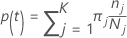
Probabilité de classe j nœud donné t:
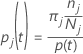
Ces définitions donnent les probabilités à l’intérieur du nœud. Minitab calcule ces probabilités pour n’importe quel nœud et n’importe quelle division potentielle. Minitab calcule l’amélioration globale d’une division potentielle de ces probabilités avec l’un des critères suivants.
Notation
| Terme | Description |
|---|---|
| K | nombre de classes dans la variable de réponse |
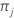 | probabilité a priori pour la classe j |
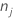 | nombre d’observations pour la classe j dans un nœud |
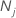 | nombre d’observations pour la classe j dans les données |
Critère de Gini
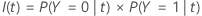
La formule plus générale suivante s’applique à une variable de réponse multinomiale :
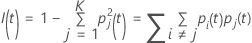
Notez que si toutes les observations pour un nœud sont dans une classe,
alors  .
.
Critère d’entropie

La formule plus générale suivante s’applique à une variable de réponse multinomiale :
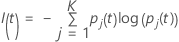
Notez que si toutes les observations pour un nœud sont dans une classe,
alors  .
.
Critère de twoing
| Super classe 1 | Super classe 2 |
|---|---|
| 1, 2, 3 | 4 |
| 1, 2, 3 | 3 |
| 1, 3, 4 | 2 |
| 2, 3, 4 | 1 |
| 1, 2 | 3, 4 |
| 1, 3 | 2, 4 |
| 1, 4 | 2, 3 |


La super classe gauche comprend toutes les classes cibles qui ont tendance à aller à gauche. La super classe droite comprend toutes les classes cibles qui ont tendance à aller à droite.
| Classe | Probabilité de nœud enfant gauche | Probabilité de nœud enfant droit |
|---|---|---|
| 1 | 0,67 | 0,33 |
| 2 | 0,82 | 0,18 |
| 3 | 0,23 | 0,77 |
| 4 | 0,89 | 0,11 |
Ensuite, la meilleure façon de créer les super classes pour la division candidate est de définir que {1, 2, 4} est une super classe et {3} l’autre super classe.
Le reste du calcul est identique au calcul du critère de Gini avec les super classes comme cible binaire.
Calcul de l’amélioration des critères
Une fois l’impureté du nœud calculée, Minitab calcule les probabilités conditionnelles de division du nœud avec un prédicteur :
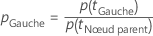
et

Ensuite, l’amélioration d’une division provient de la formule suivante :

Le fractionnement avec la valeur d’amélioration la plus élevée fait partie de l’arborescence. Si l’amélioration pour deux prédicteurs est la même, l’algorithme nécessite une sélection pour continuer. La sélection utilise un schéma de départage déterministe qui implique la position des prédicteurs dans la feuille de calcul, le type de prédicteur et le nombre de classes dans un prédicteur de catégorie.
Probabilité de classe
Les partitions de nœuds maximisent la probabilité d’une classe dans un nœud donné.
Nœuds terminaux
- Le nombre de cas dans le nœud atteint la taille minimale pour l’analyse. Le minimum par défaut dans Minitab Statistical Software est de 3.
- Tous les cas d’un nœud ont la même classe de réponse.
- Tous les cas d’un nœud ont les mêmes valeurs de prédiction.
Classe prévue pour un nœud terminal
La classe prévue pour un nœud terminal est la classe qui minimise le coût de mauvais classement pour le nœud. Les représentations du coût de mauvais classement dépendent du nombre de classes dans la variable de réponse. Etant donné que la classe prévue pour un nœud terminal provient des données d’apprentissage lorsque vous utilisez une méthode de validation, toutes les formules suivantes utilisent les probabilités de l’ensemble de données d’apprentissage.
Variable de réponse binaire
L’équation suivante donne le coût de mauvais classement pour la prédiction que les cas dans le nœud appartiennent à la classe d’événement :

L’équation suivante donne le coût de mauvais classement pour la prédiction que les cas dans le nœud appartiennent à la classe de non-événement :

| Terme | Description |
|---|---|
| PY=0|t | probabilité conditionnelle qu’un cas dans le nœud t appartienne à la classe de non-événement |
| C1|0 | coût de mauvais classement lorsque le modèle prédit à tort qu’un cas appartient à de la classe d’événement |
| PY=1|t | probabilité conditionnelle qu’un cas dans le nœud t appartienne à la classe d’événement |
| C0|1 | coût de mauvais classement lorsque le modèle prédit à tort qu’un cas appartient à de la classe de non-événement |
La classe prévue pour un nœud terminal est la classe avec le coût minimum de mauvais classement.
Variable de réponse multinomiale

Prenons, par exemple, une variable de réponse avec trois classes et les coûts de mauvais classement suivants :
| Classe prévue | |||
| Classe réelle | 1 | 2 | 3 |
| 1 | 0,0 | 4,1 | 3,2 |
| 2 | 5,6 | 0,0 | 1,1 |
| 3 | 0,4 | 0,9 | 0,0 |
Ensuite, considérez que les classes de la variable de réponse ont les probabilités suivantes pour le nœud t:
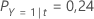
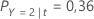

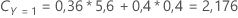


Le coût de mauvais classement le moins élevé est celui de la prédiction Y = 3, 1,164. Cette classe est la classe prévue pour le nœud terminal.