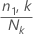La procédure pour les points de la courbe de lift dépend de la méthode de validation. Pour une variable de réponse multinomiale, Minitab affiche plusieurs courbes qui traitent chaque classe une à une comme l’événement.
Ensemble de données d’apprentissage ou aucune validation
Chaque point de la courbe d’un ensemble de données d’apprentissage représente un nœud terminal de l’arbre. Le nœud terminal avec la probabilité d’événement la plus élevée est le premier point sur la courbe et apparaît le plus à gauche. Les autres nœuds terminaux sont dans l’ordre de probabilité d’événement décroissante.
Utilisez le processus suivant pour trouver les coordonnées X et Y des points.
Calculez la probabilité d’événement de chaque nœud terminal :
où
n1,k est le nombre de cas dans la classe d’événements dans le
ke nœud
Nk est le nombre de cas dans le
ke nœud
Classez les nœuds terminaux par probabilité d’événement, de la plus élevée à la plus faible.
Pour chaque nœud terminal, attribuez les cas du nœud terminal à la classe d’événement et les cas pour les autres nœuds terminaux à la classe de non-événement
Supposons, par exemple, que le tableau suivant résume les valeurs d’un arbre avec 4 nœuds terminaux :
A : Nœud terminal
B : Nombre d’événements
C : Nombre de cas
D : Seuil (B/C)
4
18
30
0,60
1
25
67
0,37
3
12
56
0,21
2
4
36
0,11
Totaux
59
189
Les éléments suivants sont les taux de vrais positifs correspondants avec 2 chiffres après la virgule :
A : Nœud terminal
B : Nombre d’événements
C : Taux de vrais positifs
4
18
18 / 59 = 0,31
1
25
25 / 59 = 0,42
3
12
12 / 59 = 0,20
2
4
4 / 59 = 0,07
Totaux
59
A partir des nœuds terminaux triés, trouvez le pourcentage de la population dans les nœuds terminaux :
où
Nk est le nombre de cas dans le
ke nœud
N est le nombre de cas dans l’ensemble de données d'apprentissage
Pour trouver le lift de la coordonnée Y, divisez le taux de vrais positifs par le pourcentage de la population :
Pour les nœuds terminaux triés, calculez le pourcentage cumulé des données dans chaque nœud terminal. Ces valeurs cumulées sont représentées par les coordonnées X sur la courbe.
Par exemple, si le nœud terminal avec la probabilité prévue la plus élevée contient 0,16 des données et que le nœud terminal avec la deuxième probabilité d’événement la plus élevée contient 0,35 de la population, alors le pourcentage cumulé des données pour le premier nœud terminal est de 0,16 et le pourcentage cumulé de la population pour le deuxième nœud terminal est de 0,16 + 0,35 = 0,51.
Le tableau suivant montre un exemple des calculs pour un petit arbre. Les valeurs ont 2 chiffres après la virgule.
A : Nœud terminal
B : Nombre d’événements
C : Nombre de cas
D : Probabilité d’événement pour le tri (B/C)
E : Taux de vrais positifs
F : Pourcentage dans les données (C/somme de C)
G : Pourcentage cumulé dans les données, coordonnée X
H : Lift (E/F), coordonnée Y
4
18
30
0,60
0,31
0,16
0,16
1,94
1
25
67
0,37
0,42
0,35
0,51
1,20
3
12
56
0,21
0,20
0,30
0,81
0,67
2
4
36
0,11
0,07
0,19
1,00
0,37
Ensemble de données de test distinct
Suivez les mêmes étapes que pour le cas de l’ensemble de données d'apprentissage, mais calculez la probabilité d’événement à partir des cas pour l’ensemble de données de test.
Test avec validation croisée sur K partitions
La procédure de définition des coordonnées X et Y sur la courbe de lift avec validation croisée sur K partitions comporte une étape supplémentaire. Cette étape crée de nombreuses probabilités d’événement distinctes. Supposons, par exemple, que l’arborescence contienne 4 nœuds terminaux. Nous avons une validation croisée de 10 partitions. Vous utilisez ensuite une portion de 9/10 des données pour la ie partition, afin d’estimer les probabilités d’événement pour les cas de la partition i. Lorsque ce processus se répète pour chaque partition, le nombre maximal de probabilités d’événement distinctes est de 4 * 10 = 40. Ensuite, triez toutes les probabilités d’événement distinctes dans l’ordre décroissant et combinez toutes les probabilités d’événement distinctes nécessitant plus de cas pour former une cellule appropriée. Après cette étape, appliquez l’étape 3 jusqu’à la dernière étape de la procédure d’ensemble de données d'apprentissage pour trouver les coordonnées X et Y.