Sur ce thème
Composantes principales
Dans la méthode d'extraction par les composantes principales, les je contributions correspondent aux coefficients mis à l'échelle des je composantes principales. Les facteurs sont liés aux m premières composantes. Dans la solution sans rotation, vous pouvez interpréter les facteurs comme vous le feriez pour les composantes dans une analyse en composantes principales. En revanche, après la rotation, vous ne pouvez plus interpréter les facteurs comme des composantes principales.
Dans une analyse factorielle, la matrice de corrélation d'échantillon R (ou matrice de covariance S) est définie en fonction de ses paires vecteur propre-valeur propre (λi, ei), i = 1, ...,p et λ1 ≤ λ2 ≤ ... ≤ λp. Soit m < p le nombre de facteurs communs. La matrice des contributions de facteurs estimées est une matrice p × m, nommée L, dont la ie colonne comporte la valeur  , i = 1, ..., m.
, i = 1, ..., m.
Maximum de vraisemblance
La méthode du maximum de vraisemblance estime les contributions des facteurs, en supposant que les données suivent une loi normale multivariée. Comme son nom l'indique, la méthode calcule les estimations des contributions de facteurs et les variances uniques en maximisant la fonction de vraisemblance associée au modèle normal multivarié. Le même résultat peut également être obtenu en minimisant une expression qui implique les variances des valeurs résiduelles. L'algorithme est exécuté plusieurs fois, jusqu'à ce qu'un minimum soit détecté ou que le nombre maximal d'itérations spécifié (par défaut, 25) soit atteint.
Minitab utilise un algorithme fondé sur Joreskog12, avec des ajustements en vue d'améliorer la convergence. Nous résumons brièvement l'algorithme dans cette rubrique.
Supposons que nous disposons de p variables et que nous souhaitons ajuster un modèle avec m facteurs. Soit R la matrice de corrélation p × p des variables, L la matrice p × m des contributions de facteurs et Ψ une matrice diagonale p × p dont les éléments diagonaux sont les variances uniques, Ψi. Nous devons ensuite détecter les valeurs de L et Ψ qui maximisent la fonction de vraisemblance, f(L,Ψ). Cette opération requiert une procédure en deux étapes afin de détecter d'abord une valeur pour Ψ, puis pour L.
Vous pouvez indiquer la valeur initiale de Ψ de manière indirecte. Dans la sous-boîte de dialogue Analyse factorielle : Options, indiquez la colonne contenant les valeurs initiales des communalités dans la zone Utiliser l'estimation de communalité initiale dans. Minitab calcule ensuite les éléments diagonaux de Ψ comme égaux à (1 − communalités).
Pour une valeur fixe de Ψ, nous maximisons f(L,Ψ) en fonction de L. Il s'agit d'un calcul matriciel simple. La valeur de L est ensuite utilisée dans la fonction f(L,Ψ), ce qui fait que f peut ainsi être considérée comme une fonction de Ψ. Une transformation simple de cette fonction fournit la fonction suivante :
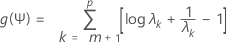
où λ1 < λ2 < ... λp sont des valeurs propres de Ψ R- 1Ψ. Nous minimisons ensuite g(Ψ), à l'aide d'une procédure de Newton-Raphson. Cette opération fournit une estimation de Ψ qui est ensuite utilisée dans la fonction de vraisemblance f(L,Ψ). Cette fonction de vraisemblance est à nouveau maximisée en fonction de L, une nouvelle valeur est calculée pour g(Ψ), et ainsi de suite. Par défaut, les itérations continuent jusqu'à 25 étapes si la convergence n'est pas atteinte. Si l'algorithme n'atteint pas la convergence au bout de 25 étapes, vous pouvez modifier le nombre maximal d'itérations par défaut dans la sous-boîte de dialogue Options.
La convergence est atteinte à l'étape n, si l'une des conditions suivantes est vérifiée :
- La fonction g(Ψ) ne varie pas beaucoup entre les étapes consécutives. Plus spécifiquement, si :
- | [g(Ψ) à l'étape n] − [g(Ψ) à l'étape (n − 1)] | < 10-6
- Aucune des variances uniques ne varie beaucoup entre les étapes consécutives. Plus spécifiquement, si :
- | ln(Ψi à l'étape n) − ln(Ψi à l'étape n − 1) | < K2,
pour tout i = 1, ... , p, où Ψi, le ie élément diagonal de Ψ, est la variance unique correspondant à la variable i.
La valeur de K2 peut être indiquée dans la zone Convergence de la sous-boîte de dialogue Options. Par défaut, la valeur est de 0,005.
Sélectionnez Itérations EMaxV et toutes itérations dans la sous-boîte de dialogue Résultats pour afficher les informations relatives à chaque itération. La valeur de la fonction objectif, g(Ψ), est affichée, puis le maximum change dans ln(Ψi). Si, lors d'une itération, la valeur de g(Ψ) ne diminue pas, un valeur d'étape plus petite (moitié de la taille) est utilisée. Les demi-étapes continuent jusqu'à ce que g(Ψ) diminue ou que 25 demi-étapes soient réalisées. Le nombre de demi-étapes est affiché. Si g(Ψ) n'a pas diminué lors des 25 demi-étapes, l'algorithme s'arrête et un message apparaît.
Une matrice des dérivées secondes est utilisée pour la minimisation de g(Ψ). Cette matrice n'est pas toujours définie positive. Si elle ne l'est pas, une approximation est utilisée. Un astérisque apparaît sur les résultats lorsque Minitab utilise la matrice exacte.
Lors de la minimisation de la fonction g(Ψ), vosu pouvez rencontrer des éléments de la diagonale de Ψ dont la valeur est nulle ou négative. Pour éviter cela, l'algorithme de Minitab établit une limite pour les éléments diagonaux de Ψ afin de les éloigner de 0. Plus spécifiquement, si une variance unique Ψi est inférieure à K2, elle est définie comme égale à K2. K2 est la valeur définie dans Convergence dans la sous-boîte de dialogue Options.
Lorsque l'algorithme converge, une vérification finale est effectuée sur les variances uniques. Si des variances uniques sont inférieures à K2, elles sont définies comme égales à 0. La communalité correspondante est alors égale à 1. Ce résultat est appelé cas Heywood et Minitab affiche un message pour en informer l'utilisateur. Les algorithmes d'optimisation, comme celui utilisé pour l'analyse factorielle par vraisemblance, peuvent fournir des réponses différentes si vous apportez des modifications minimes dans les entrées. Par exemple, si vous modifiez quelques points de données, les valeurs de départ dans Utiliser l'estimation de communalité initiale dans ou le critère de convergence dans Convergence, vous pouvez constater des différences dans les résultats de l'analyse factorielle. Cela est particulièrement vrai si la solution se trouve sur une portion relativement plate de la surface du maximum de vraisemblance.
Rotation des contributions
Une rotation orthogonale est une transformation orthogonale des contributions de facteurs qui permet d'interpréter plus facilement les contributions de facteurs. Les contributions auxquelles une rotation est appliquée conservent la matrice de corrélation ou de covariance, la matrice des valeurs résiduelles, les variances spécifiques et les communalités. Comme les contributions changent, la variance expliquée par chaque facteur et la proportion correspondante changent aussi.
La rotation place les axes à proximité d'autant de points que possible et associe chaque groupe de variables à un facteur. Cependant, dans certains cas, une variable peut être proche de plusieurs axes et est alors associée à plusieurs facteurs.
Vous pouvez choisir parmi quatre méthodes de rotation :
- Equimax : maximise la variance des contributions quadratiques au sein des variables et des facteurs.
- Varimax : maximise la variance des contributions quadratiques au sein des facteurs. Cette méthode simplifie les colonnes de la matrice des contributions et représente la méthode de rotation la plus utilisée. Pour faciliter l'interprétation, cette méthode tente de rendre les contributions importantes ou faibles.
- Quartimax : maximise la variance des contributions quadratiques au sein des variables. Cette méthode simplifie les lignes de la matrice des contributions.
- Orthomax avec γ : rotation comprenant les trois méthodes ci-dessus en fonction de la valeur du paramètre gamma (0-1).
Modèle d'analyse factorielle
Le modèle d'analyse factorielle est le suivant :
X = μ + L F + e
où X est le vecteur p x 1 des mesures, μ est le vecteur p x 1 des moyennes, L est une matrice p × m des contributions, F est un vecteur m × 1 des facteurs communs et e est un vecteur p × 1 des valeurs résiduelles. Ici, p représente le nombre de mesures sur un sujet ou un item et m représente le nombre de facteurs communs. F et e sont supposés indépendants et les valeurs F individuelles sont indépendantes entre elles. La moyenne de F et e est égale à 0, Cov(F) = I, la matrice d'identité, et Cov(e) = Ψ, une matrice diagonale. En raison des hypothèses sur l'indépendance des valeurs F, ce modèle est un modèle factoriel orthogonal.
Sous le modèle d'analyse factorielle, la matrice de covariance p × p des données, X, est calculée comme suit :
Cov(X) = L L' + Ψ
où L est la matrice p × m des contributions et Ψ est une matrice diagonale p × p. Le ie élément diagonal de L L', la somme des contributions quadratiques, est appelé la ie communalité. Les valeurs de communalité peuvent être considérées comme le pourcentage de variabilité expliqué par les facteurs communs. Le ie élément diagonal de Ψ est appelé la ie variance spécifique, ou unicité. La variance spécifique est la part de la variabilité non expliquée par les facteurs communs. Vous pouvez vous fonder sur les valeurs de communalité et/ou les variances spécifiques pour évaluer l'adéquation de l'ajustement.
Contributions
Formule
Lorsque la méthode des composantes principales est utilisée, la matrice des contributions de facteurs estimées, L, est calculée comme suit :
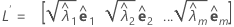
Lorsque la méthode du maximum de vraisemblance est utilisée, la matrice des contributions de facteurs est obtenue à l'aide d'une procédure itérative.
Notation
| Terme | Description |
|---|---|
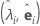 | paires vecteurs propres-valeurs propres |
Communalités
Formule
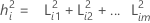
où i = 1, 2 ... p
Notation
| Terme | Description |
|---|---|
| L | matrice des contributions des facteurs |
Variance
Variabilité dans les données expliquée par chaque facteur. La variance est égale à la valeur propre si vous utilisez des composantes principales pour extraire les facteurs et que vous n'effectuez pas de rotation des contributions.
% var
Formule
Lorsqu'une matrice de corrélation est utilisée, la proportion de la variance expliquée par le je facteur est calculée comme suit :
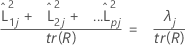
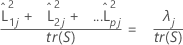
Notation
| Terme | Description |
|---|---|
| L | matrice des contributions des facteurs |
| λj | je valeur propre |
| tr(R) | trace de la matrice de corrélation |
| tr(S) | trace de la matrice de covariance |
Coefficients
Formule
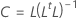
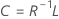
R représente la matrice de corrélation. Si vous utilisez la matrice de covariance comme matrice à facteur, alors R est remplacé par la matrice de covariance.
Notation
| Terme | Description |
|---|---|
| L | matrice des contributions des facteurs |
Scores
Formule
F = ZC
Notation
| Terme | Description |
|---|---|
| F | matrice des scores factoriels |
| Z | données normalisées |
| C | matrice des coefficients des scores factoriels |