Sur ce thème
Distance quadratique
Distance quadratique de Mahalanobis - Formule générale
La distance quadratique (également appelée la distance de Mahalanobis) entre l'observation x et le centre (moyenne) du groupe t pour la fonction discriminante linéaire est donnée par la formule générale suivante :

Distance quadratique de Mahalanobis - Fonction quadratique
La distance quadratique de Mahalanobis séparant x du groupe t pour la fonction discriminante quadratique est calculée comme suit :

Distance quadratique généralisée - Fonction linéaire
La distance quadratique généralisée séparant x du groupe t pour la fonction discriminante linéaire est calculée comme suit :
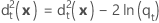
Distance quadratique généralisée - Fonction quadratique
La distance quadratique généralisée séparant x du groupe t pour la fonction discriminante quadratique est calculée comme suit :

Probabilité a posteriori
La probabilité a posteriori pour x appartenant au groupe t se calcule comme suit :
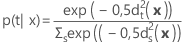
Scores discriminants linéaires
Les scores discriminants linéaires sont calculés comme suit :

Notation
| Terme | Description |
|---|---|
| x | vecteur de colonne de longueur p contenant les valeurs des prédicteurs pour cette observation (ce vecteur de colonne est stocké en tant que ligne) |
| p | nombre de prédicteurs |
| n | nombre total d'observations |
| t | indice de groupe |
| nt | nombre d'observations dans le groupe t |
| qt | probabilité a priori du groupe t, égale à nt/n |
| Sp | matrice de covariance groupée de l'analyse discriminante linéaire |
| Si | matrice de covariance du groupe i de l'analyse discriminante quadratique |
| mt | vecteur de colonne de longueur p contenant les moyennes des prédicteurs calculées à partir des données du groupe t |
| St | matrice de covariance du groupe t |
| |St| | déterminant de St |
Fonction discriminante linéaire

Pour une valeur x donnée, cette règle affecte x au groupe ayant la plus grande fonction discriminante linéaire.
Notation
| Terme | Description |
|---|---|
| x | vecteur de colonne de longueur p contenant les valeurs des prédicteurs pour cette observation (ce vecteur de colonne est stocké en tant que ligne) |
| mi | vecteur de colonne de longueur p contenant les moyennes des prédicteurs calculées à partir des données du groupe i |
| Sp | matrice de covariance groupée |
| ln pi | logarithme népérien de la probabilité a priori du groupe i |
Distance quadratique généralisée

Notation
| Terme | Description |
|---|---|
| x | vecteur de colonne de longueur p contenant les valeurs des prédicteurs pour cette observation (ce vecteur de colonne est stocké en tant que ligne) |
| mi | vecteur de colonne de longueur p contenant les moyennes des prédicteurs calculées à partir des données du groupe i |
| Sp | matrice de covariance groupée f |
| ln pi | logarithme népérien de la probabilité a priori du groupe i |
Probabilité a posteriori
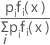
La probabilité a posteriori la plus grande est équivalente à la plus grande valeur de ln [pi fi (x)]


Notation
| Terme | Description |
|---|---|
| pi | probabilité a priori du groupe i |
| fi(x) | densité jointe pour les données du groupe i (les paramètres de population étant remplacés par les estimations de l'échantillon) |