Sur ce thème
Etape 1 : Examiner les niveaux de similarité et de distance
A chaque étape du processus de fusion, visualisez les groupes formés et examinez leurs niveaux de similarité et de distance. Plus le niveau de similarité est élevé, plus les variables sont similaires (corrélées) dans chaque groupe. Plus le niveau de distance est faible, plus les variables sont proches dans chaque groupe.
Dans l'idéal, les groupes doivent avoir un niveau de similarité relativement élevé et un niveau de distance relativement faible. Cependant, vous devez trouver un équilibre entre cet objectif et le fait de disposer d'un nombre de groupes raisonnable et pratique.
Etapes de fusion
| Etape | Nombre de groupes | Niveau de similarité | Niveau de distance | Groupes liés | Nouveau groupe | Nombre d'obs. dans le nouveau groupe | |
|---|---|---|---|---|---|---|---|
| 1 | 4 | 93,9666 | 0,120669 | 2 | 3 | 2 | 2 |
| 2 | 3 | 93,1548 | 0,136904 | 4 | 5 | 4 | 2 |
| 3 | 2 | 87,3150 | 0,253700 | 1 | 4 | 1 | 3 |
| 4 | 1 | 79,8113 | 0,403775 | 1 | 2 | 1 | 5 |
Résultats principaux : niveau de similarité, niveau de distance
Dans ces résultats, les données contiennent un total de 5 variables. A l'étape 1, deux groupes (variables 2 et 3 de la feuille de travail) sont liés pour former un nouveau groupe. Cette opération crée 4 groupes dans les données, avec un niveau de similarité de 93,9666 et un niveau de distance de 0,130669. Bien que le niveau de similarité soit élevé et que le niveau de distance soit faible, le nombre de groupes est trop élevé pour être utile. Lors des étapes suivantes, tandis que de nouveaux groupes sont formés, le niveau de similarité diminue et le niveau de distance augmente. Lors de la dernière étape, toutes les variables sont liées en un seul groupe.
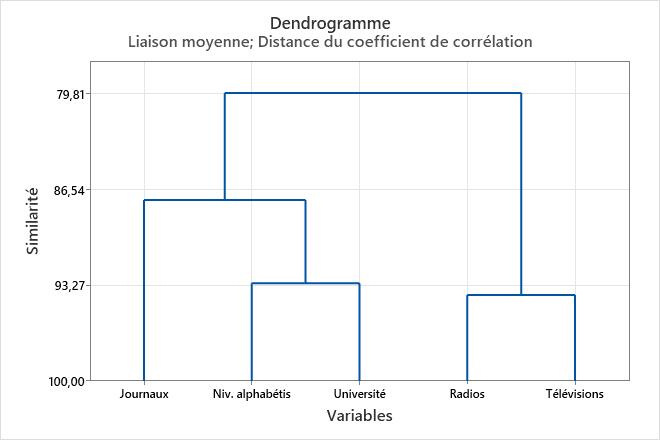
Pour visualiser les niveaux de similarité du dendrogramme, positionnez le pointeur de la souris sur une ligne horizontale de l'arborescence dans Minitab.
Etape 2 : Déterminer les groupements finaux pour vos données
Utilisez le niveau de similarité pour les groupes qui sont liés à chaque étape afin de déterminer les groupements finaux de données.Recherchez un changement brusque dans le niveau de similarité entre les étapes. L'étape qui précède le changement brusque dans la similarité peut représenter un point de limitation approprié pour la subdivision finale. Pour la subdivision finale, les groupes doivent présenter un niveau de similarité raisonnablement élevé. Vous devez également utiliser vos connaissances pratiques des données pour déterminer les groupements finaux les plus pertinents dans votre application.
Par exemple, le tableau de fusion suivant indique que le niveau de similarité diminue légèrement de l'étape 1 (93,9666) à l'étape 2 (93,1548). La similarité diminue ensuite brusquement lors de l'étape 3 (87,3150), lorsque le nombre de groupes passe de 3 à 2. Ces résultats indiquent que 3 groupes peuvent suffire à constituer la subdivision finale. Si ce groupement semble intuitivement logique, ce peut être le bon choix.
Etapes de fusion
| Etape | Nombre de groupes | Niveau de similarité | Niveau de distance | Groupes liés | Nouveau groupe | Nombre d'obs. dans le nouveau groupe | |
|---|---|---|---|---|---|---|---|
| 1 | 4 | 93,9666 | 0,120669 | 2 | 3 | 2 | 2 |
| 2 | 3 | 93,1548 | 0,136904 | 4 | 5 | 4 | 2 |
| 3 | 2 | 87,3150 | 0,253700 | 1 | 4 | 1 | 3 |
| 4 | 1 | 79,8113 | 0,403775 | 1 | 2 | 1 | 5 |
Résultats principaux : niveau de similarité, nombre de groupes
On désigne également le choix du regroupement final par l'expression "couper le dendrogramme". Couper le dendrogramme revient à tracer une ligne horizontale à travers le dendrogramme pour spécifier le groupement final. Par exemple, pour couper ce dendrogramme en quatre groupes, imaginez que vous tracez une ligne horizontale à peu près à la moitié de l'axe vertical, juste en dessous du niveau de similarité d'environ 88.
Etape 3 : Examiner la subdivision finale
Après avoir déterminé les groupements finaux lors de l'étape 2, répétez l'analyse et spécifiez le nombre de groupes (ou le niveau de similarité) de la subdivision finale. Minitab affiche le tableau de la subdivision finale, indiquant les variables formant chaque groupe.
Examinez les groupes dans la subdivision finale afin de déterminer si le groupement semble logique pour votre application. Si vous avez toujours un doute, vous pouvez répéter l'analyse et comparer les dendrogrammes de différents groupements finaux pour vous aider à choisir le plus logique par rapport à vos données.
Etapes de fusion
| Etape | Nombre de groupes | Niveau de similarité | Niveau de distance | Groupes liés | Nouveau groupe | Nombre d'obs. dans le nouveau groupe | |
|---|---|---|---|---|---|---|---|
| 1 | 4 | 93,9666 | 0,120669 | 2 | 3 | 2 | 2 |
| 2 | 3 | 93,1548 | 0,136904 | 4 | 5 | 4 | 2 |
| 3 | 2 | 87,3150 | 0,253700 | 1 | 4 | 1 | 3 |
| 4 | 1 | 79,8113 | 0,403775 | 1 | 2 | 1 | 5 |
Subdivision finale
| Variables | |
|---|---|
| Groupe 1 | Journaux |
| Groupe 2 | Radios Télévisions |
| Groupe 3 | Niv. alphabétis Université |
Résultats principaux : subdivision finale, dendrogramme
Dans ces résultats, les trois groupes suivants sont formés dans la subdivision finale :
- Nombre de journaux par groupe de 1 000 personnes
- Nombre de radios et de postes de télévision
- Niveau d'alphabétisation et présence ou non d'une université dans la ville
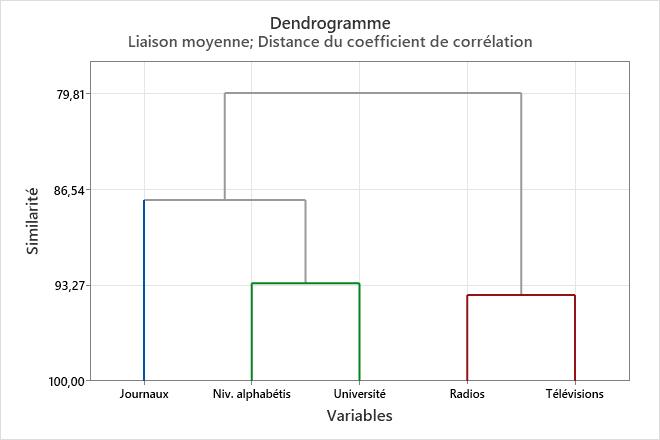
Ce dendrogramme a été créé avec une subdivision finale de 3 groupes. Chaque groupe final est signalé par une couleur différente. Le dendrogramme a été coupé à un niveau de similarité d'environ 88. Si le dendrogramme avait été coupé plus haut, les groupes finaux seraient moins nombreux, mais le niveau de similarité serait réduit. Si le dendrogramme avait été coupé plus bas, le niveau de similarité aurait été supérieur, mais les groupes finaux seraient plus nombreux.