Sur ce thème
Etape
Numéro de l'étape dans la procédure de fusion permettant de lier les groupes. A chaque étape, un nouveau groupe est lié à un groupe existant et leurs niveaux de similarité et de distance sont calculés.
Nombre de groupes
Nombre de groupes formés à chaque étape du processus de fusion. Avant la première étape, le nombre de groupes correspond au nombre total d'observations (pour les observations en groupes) ou au nombre total de variables (pour les variables de groupes). Lors de la première étape, deux groupes sont liés pour en former un nouveau. A chaque étape suivante, un autre groupe est lié à un groupe existant pour former un nouveau groupe. Lors de la dernière étape, toutes les observations ou variables sont combinées en un seul groupe.
Vous pouvez entrer le nombre de groupes dans la boîte de dialogue principale pour spécifier la subdivision finale de vos données. La méthode de liaison et la mesure de distance choisies influencent considérablement les résultats du regroupement.
Niveau de similarité
Pourcentage de la distance minimale entre les groupes à chaque étape de fusion par rapport à la distance maximale entre les observations dans les données. La similarité s(ij) entre deux groupes i et j s'obtient avec s(ij) = 100 * [1 - d(ij)) / d(max)], d(max) étant la valeur maximale existant dans la matrice de distance D d'origine et d(ij) étant la distance entre i et j.
Interprétation
Utilisez le niveau de similarité pour les groupes qui sont liés à chaque étape afin de déterminer les groupements finaux de données.Recherchez un changement brusque dans le niveau de similarité entre les étapes. L'étape qui précède le changement brusque dans la similarité peut représenter un point de limitation approprié pour la subdivision finale. Pour la subdivision finale, les groupes doivent présenter un niveau de similarité raisonnablement élevé. Vous devez également utiliser vos connaissances pratiques des données pour déterminer les groupements finaux les plus pertinents dans votre application.
Par exemple, le tableau de fusion suivant indique que le niveau de similarité diminue légèrement de l'étape 1 (93,9666) à l'étape 2 (93,1548). La similarité diminue ensuite brusquement lors de l'étape 3 (87,3150), lorsque le nombre de groupes passe de 3 à 2. Ces résultats indiquent que 3 groupes peuvent suffire à constituer la subdivision finale. Si ce groupement semble intuitivement logique, ce peut être le bon choix.
Etapes de fusion
| Etape | Nombre de groupes | Niveau de similarité | Niveau de distance | Groupes liés | Nouveau groupe | Nombre d'obs. dans le nouveau groupe | |
|---|---|---|---|---|---|---|---|
| 1 | 4 | 93,9666 | 0,120669 | 2 | 3 | 2 | 2 |
| 2 | 3 | 93,1548 | 0,136904 | 4 | 5 | 4 | 2 |
| 3 | 2 | 87,3150 | 0,253700 | 1 | 4 | 1 | 3 |
| 4 | 1 | 79,8113 | 0,403775 | 1 | 2 | 1 | 5 |
Niveau de distance
Distance séparant les groupes (avec la méthode de liaison choisie) ou les variables (avec la mesure de distance choisie) liés à chaque étape. Minitab calcule le niveau de distance en fonction de la méthode de liaison et de la mesure de distance sélectionnées dans la boîte de dialogue principale.
La distance séparant deux variables se rapporte directement à leur corrélation. Autrement dit, pour deux variables, X1 et X2, la distance est égale à 1− Corrélation. Par exemple, si Corr(X1,X2) = 0,879, alors Distance(X1,X2) = 1 − 0,879 = 0,121.
Interprétation
Utilisez le niveau de distance pour les groupes qui sont liés à chaque étape afin de déterminer les groupements finaux de données. Recherchez un changement brusque dans le niveau de distance entre les étapes. L'étape qui précède le changement brusque dans la distance peut représenter un point de limitation approprié pour la subdivision finale. Pour la subdivision finale, les groupes doivent présenter un niveau de distance raisonnablement réduit. Vous devez également utiliser vos connaissances pratiques des données pour déterminer les groupements finaux les plus pertinents dans votre application.
Par exemple, le tableau de fusion suivant indique que le niveau de distance augmente légèrement entre l'étape 1 (0,120669) et l'étape 2 (0,136904). La distance augmente ensuite plus brusquement lors de l'étape 3 (0,253700), lorsque le nombre de groupes passe de 3 à 2. Ces résultats indiquent que 3 groupes peuvent suffire à constituer la subdivision finale. Si ce groupement semble intuitivement logique, ce peut être le bon choix.
Etapes de fusion
| Etape | Nombre de groupes | Niveau de similarité | Niveau de distance | Groupes liés | Nouveau groupe | Nombre d'obs. dans le nouveau groupe | |
|---|---|---|---|---|---|---|---|
| 1 | 4 | 93,9666 | 0,120669 | 2 | 3 | 2 | 2 |
| 2 | 3 | 93,1548 | 0,136904 | 4 | 5 | 4 | 2 |
| 3 | 2 | 87,3150 | 0,253700 | 1 | 4 | 1 | 3 |
| 4 | 1 | 79,8113 | 0,403775 | 1 | 2 | 1 | 5 |
Groupes liés
Deux groupes liés pour former un nouveau groupe à chaque étape du processus de fusion.
Nouveau groupe
Numéro d'identification du nouveau groupe formé à chaque étape du processus de fusion. Le numéro d'identification du nouveau groupe est toujours le plus petit des numéros des deux groupes liés. Par exemple, si le groupe 2 est lié au groupe 9, le nouveau groupe qui est formé s'appelle groupe 2.
Nombre d'observations dans un nouveau groupe
Nombre d'observations dans tout nouveau groupe à chaque étape du processus de fusion. Lors de la dernière étape, toutes les observations sont combinées en un seul groupe. C'est pourquoi le nombre d'observations dans le nouveau groupe pour la dernière étape est égal au nombre total d'observations dans les données.
Remarque
Pour la fonction Variables de groupes, le nombre d'observations correspond au nombre de variables dans le nouveau groupe.
Subdivision finale
Si vous avez spécifié une subdivision finale dans la boîte de dialogue principale, Minitab affiche une liste des variables dans chaque groupe. Les variables contenues dans chaque groupe de la subdivision finale doivent être logiques, en fonction de votre application particulière.
Dendrogramme
Le dendrogramme est une arborescence qui affiche les groupes formés par le regroupement des variables à chaque étape et leurs niveaux de similarité. Le niveau de similarité est mesuré le long de l'axe vertical (alternativement, vous pouvez afficher le niveau de distance) et les différentes variables sont répertoriées le long de l'axe horizontal.
Interprétation
Utilisez le dendrogramme pour visualiser le mode de formation des groupes à chaque étape et pour évaluer les niveaux de similarité (ou de distance) des groupes formés.
Pour visualiser les niveaux de similarité (ou de distance), positionnez le pointeur de la souris sur une ligne horizontale du dendrogramme. La configuration de variation des valeurs de similarité ou de distance d'une étape à une autre peut vous aider à sélectionner le groupement final pour vos données. L'étape comportant un changement brusque des valeurs peut correspondre à un point intéressant pour définir le groupement final.
On désigne également le choix du regroupement final par l'expression "couper le dendrogramme". Couper le dendrogramme revient à tracer une ligne à travers le dendrogramme pour spécifier le groupement final. Vous pouvez également comparer différents groupements finaux dans les dendrogrammes pour choisir le plus logique pour vos données.
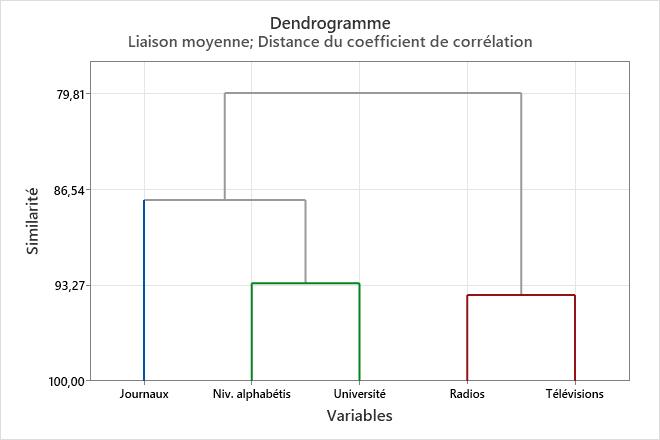
Ce dendrogramme a été créé en utilisant une subdivision finale en 3 groupes. Chaque groupe final est signalé par une couleur différente. Le dendrogramme a été "coupé" à un niveau de similarité à peu près égal à 88. Si le dendrogramme avait été coupé plus haut, les groupes finaux seraient moins nombreux, mais le niveau de similarité serait réduit. Si le dendrogramme avait été coupé plus bas, le niveau de similarité aurait été supérieur, mais les groupes finaux seraient plus nombreux.
Remarque
Pour certains fichiers de données, les méthodes moyenne, centroïde, médiane et Ward peuvent ne pas produire de dendrogramme hiérarchique. Autrement dit, les distances de fusion n'augmentent pas automatiquement après chaque étape. Dans le dendrogramme, cela produit une liaison descendante et non ascendante.