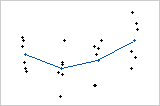
Dans les deux graphiques des valeurs individuelles ci-dessous, les ensembles de données ont exactement les mêmes moyennes pour les niveaux de facteur. Par conséquent, la variabilité dans les données due au facteur est identique dans les deux ensembles de données. En observant ces graphiques, vous pourriez être tenté de conclure que les moyennes sont différentes dans les deux cas. Remarquez toutefois que la variabilité à l'intérieur des niveaux des facteurs est beaucoup plus grande dans le second ensemble de données que dans le premier.
Pour évaluer les différences entre les moyennes, vous devez comparer ces différences à la dispersion des observations autour des moyennes. C'est exactement ce que fait l'analyse de la variance. Avec une analyse de la variance, la valeur de p correspondant au premier graphique est de 0,00 alors que la valeur de p correspondant au second graphique est de 0,109.
Par conséquent, en utilisant un seuil de signification de 0,05, le test révèle que, dans le premier fichier de données, les moyennes sont significativement différentes. En revanche, il est très possible que les différences entre les moyennes d'échantillons dans le second ensemble de données soient le résultat aléatoire de la grande variabilité globale dans les données.
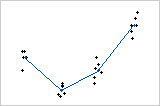
Graphique à faible variabilité