Sur ce thème
S
S représente l'écart type entre les valeurs de données et les valeurs ajustées. S est mesuré dans les unités de la réponse.
Interprétation
Utilisez S pour évaluer la capacité du modèle à décrire la réponse. S est mesuré en unités de la variable de réponse et représente la distance entre les valeurs de données et les valeurs ajustées. Plus S est petit, mieux le modèle décrit la réponse. Cependant, une faible valeur de S n'indique pas en soi que le modèle respecte les hypothèses du modèle. Vous devez examiner les graphiques des valeurs résiduelles pour vérifier les hypothèses.
Par exemple, vous travaillez pour un fabricant de pommes chips qui étudie les facteurs jouant sur le pourcentage de chips brisées par conteneur. Vous réduisez le modèle jusqu'à ne conserver que les prédicteurs significatifs, et vous constatez que S a pour valeur 1,79. Ce résultat indique que l'écart type des points de données autour des valeurs ajustées est 1,79. Si vous comparez des modèles, les valeurs inférieures à 1,79 indiquent un meilleur ajustement, tandis que les valeurs supérieures indiquent un moins bon ajustement.
R carré
R2 représente le pourcentage de variation de la réponse expliqué par le modèle. Cette valeur est calculée comme 1 moins le rapport de la somme des carrés de l'erreur (variation non expliquée par le modèle) sur la somme totale des carrés (variation totale du modèle).
Interprétation
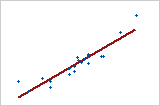
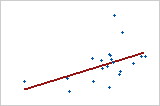
Utilisez la valeur R2 pour déterminer l'ajustement du modèle à vos données. Plus la valeur R2 est élevée, plus le modèle est ajusté à vos données. R2 est toujours compris entre 0 et 100 %.
-
La valeur R2 augmente toujours lorsque vous ajoutez des prédicteurs à un modèle. Par exemple, le meilleur modèle à 5 prédicteurs aura toujours une valeur R2 au moins aussi élevée que celle du meilleur modèle à 4 prédicteurs. Par conséquent, R2 est surtout utile pour comparer des modèles de même taille.
-
Les petits échantillons ne fournissent pas d'estimation précise de la force de la relation entre la réponse et les prédicteurs. Par exemple, pour obtenir une valeur R2 plus précise, vous devez utiliser un échantillon plus grand (en général, 40 ou plus).
-
Les statistiques d'adéquation de l'ajustement ne sont qu'un des types de mesures permettant d'évaluer l'ajustement du modèle. Même si un modèle a une valeur souhaitable, vous devez consulter les graphiques des valeurs résiduelles pour vérifier que le modèle respecte les hypothèses.
R carré (ajust)
Le R2 ajusté est le pourcentage de la variation de la réponse qui est expliqué par le modèle, ajusté au nombre de prédicteurs du modèle par rapport au nombre d'observations. Le R2 ajusté est égal à 1 moins le rapport entre le carré moyen de l'erreur (CME) et le carré moyen total (CM Total).
Interprétation
Utilisez la valeur R2 ajusté pour comparer des modèles n'ayant pas le même nombre de prédicteurs. R2 augmente toujours lorsque vous ajoutez un prédicteur au modèle, même lorsque ce prédicteur n'apporte aucune amélioration réelle au modèle. La valeur de R2 ajusté intègre le nombre de prédicteurs dans le modèle pour vous aider à choisir le modèle correct.
| Modèle | % de pomme de terre | Vitesse de refroidissement | Température de cuisson | R2 | R2 ajusté |
|---|---|---|---|---|---|
| 1 | X | (-52@, 0@, +1) | (-51@, 0@, +1) | ||
| 2 | X | X | (-63@, 0@, +1) | (-62@, 0@, +1) | |
| 3 | X | X | X | (-65@, 0@, +1) | (-62@, 0@, +1) |
Le premier modèle présente une valeur de R2 de plus de 50 %. Le deuxième modèle ajoute la vitesse de refroidissement au modèle. La valeur R2 ajusté augmente, ce qui indique que la vitesse de refroidissement améliore le modèle. Le troisième modèle, qui inclut la température de cuisson, augmente la valeur R2 mais pas la valeur R2 ajusté. Ces résultats indiquent que la température de cuisson n'améliore pas le modèle. Selon ces résultats, vous devriez supprimer la température de cuisson du modèle.