Moyennes
Le tableau des moyennes affiche les moyennes ajustées des observations dans les groupes en fonction d'une ou plusieurs variables de catégorie. Les moyennes ajustées utilisent les moindres carrés pour prévoir les valeurs de réponse d'un plan équilibré.
Interprétation
Les moyennes ajustées estiment la réponse moyenne à différents niveaux d'un facteur tout en faisant la moyenne des niveaux des autres facteurs.
Utilisez le tableau des moyennes pour voir les différences qui sont statistiquement significatives entre les niveaux de facteurs dans vos données. La moyenne de chaque groupe fournit une estimation de la moyenne de chaque population. Recherchez les différences entre les moyennes des groupes pour les termes qui sont statistiquement significatifs.
Pour les effets principaux, le tableau affiche les groupes propres à chaque facteur, ainsi que leurs moyennes. Pour les effets d'interaction, le tableau affiche toutes les combinaisons de groupes possibles. Si un terme d'interaction est statistiquement significatif, vous ne pouvez pas interpréter les effets principaux sans tenir compte des effets d'interaction.
Dans ces résultats, le tableau des moyennes indique dans quelle mesure les évaluations de qualité et de commodité moyennes varient en fonction de la méthode, de l'usine et de l'interaction Méthode*Usine. La méthode et le terme d'interaction sont statistiquement significatifs au seuil de 0,10. Le tableau indique que la méthode 1 et la méthode 2 sont associées à des évaluations de commodité moyennes de 4,819 et 6,212 respectivement. La différence entre ces moyennes est plus importante que la différence entre les moyennes correspondantes pour l'évaluation de la qualité. Cela confirme l'interprétation de l'analyse des valeurs et vecteurs propres.
Toutefois, étant donné que le terme d'interaction Méthode*Usine est lui aussi statistiquement significatif, vous ne pouvez pas interpréter les effets principaux sans tenir compte des effets d'interaction. Par exemple, le tableau du terme d'interaction indique qu'avec la méthode 1, l'usine C est associée à l'évaluation de commodité la plus élevée et à l'évaluation de qualité la plus faible. En revanche, avec la méthode 2, l'usine A est associée à l'évaluation de commodité la plus élevée et à une évaluation de qualité qui est presque égale à la plus élevée.
Moyennes issues des moindres carrés pour les réponses
| Eval commodité | Eval qualité | |||
|---|---|---|---|---|
| Moyenne | ErT moyenne | Moyenne | ErT moyenne | |
| Méthode | ||||
| Méthode 1 | 4,819 | 0,165 | 5,242 | 0,193 |
| Méthode 2 | 6,212 | 0,179 | 6,026 | 0,211 |
| Usine | ||||
| Usine A | 5,708 | 0,192 | 5,833 | 0,226 |
| Usine B | 5,493 | 0,232 | 5,914 | 0,273 |
| Usine C | 5,345 | 0,206 | 5,155 | 0,242 |
| Méthode*Usine | ||||
| Méthode 1 Usine A | 4,667 | 0,272 | 5,417 | 0,319 |
| Méthode 1 Usine B | 4,700 | 0,298 | 5,400 | 0,350 |
| Méthode 1 Usine C | 5,091 | 0,284 | 4,909 | 0,334 |
| Méthode 2 Usine A | 6,750 | 0,272 | 6,250 | 0,319 |
| Méthode 2 Usine B | 6,286 | 0,356 | 6,429 | 0,418 |
| Méthode 2 Usine C | 5,600 | 0,298 | 5,400 | 0,350 |
ErT moyenne
L'erreur type de la moyenne (ErT moyenne) estime la variabilité entre les moyennes ajustées que vous obtiendriez si vous preniez des échantillons répétés de la même population.
Par exemple, vous disposez d'un délai de livraison moyen de 3,80 jours avec un écart type de 1,43 jour, basé sur un échantillon aléatoire de 312 délais de livraison. Ces chiffres génèrent une erreur type de la moyenne de 0,08 jour (1,43 divisé par la racine carrée de 312). Si vous preniez en compte plusieurs échantillons aléatoires de même effectif et provenant de la même population, l'écart type de ces différentes moyennes d'échantillons tournerait autour de 0,08 jour.
Interprétation
Utilisez l'erreur type de la moyenne pour déterminer avec quelle précision la moyenne ajustée évalue la moyenne de la population.
Lorsque la valeur de l'erreur type de la moyenne est moins élevée, l'estimation de la moyenne de la population est plus précise. En règle générale, plus l'écart type est grand, plus l'erreur type de la moyenne est élevée et moins l'estimation de la moyenne de la population est précise. En revanche, plus l'effectif d'échantillon est élevé, plus l'erreur type de la moyenne est faible et plus l'estimation de la moyenne de la population est précise.
Moyenne (covariable)
La moyenne de la covariable est la moyenne des données, c'est-à-dire la somme de toutes les observations, divisée par le nombre d'observations. La moyenne résume les valeurs d'échantillons en une seule valeur représentant le centre des données.
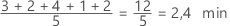
Interprétation
Utilisez la moyenne pour décrire la covariable avec une seule valeur qui représente le centre des données.
Ecart type (EcTyp)
L'écart type est la mesure la plus courante de la dispersion ou de la répartition des données autour la moyenne. Le symbole σ (sigma) représente souvent l'écart type d'une population. La lettre s est souvent utilisée pour représenter l'écart type d'un échantillon.
Interprétation
- Environ 68 % des valeurs se situent à moins d'un écart type de la moyenne.
- 95 % des valeurs se situent à moins de deux écarts types.
- 99,7 % des valeurs se situent à moins de trois écarts types.
L'écart type d'échantillon d'un groupe est une estimation de l'écart type de la population de ce groupe. Les écarts types permettent de calculer les intervalles de confiance et les valeurs de p. Plus les écarts types d'échantillon sont élevés, moins les intervalles de confiance sont précis (ils sont plus larges) et moins les statistiques sont efficaces.
L'analyse de la variance suppose que les écarts types de population pour chaque niveau sont égaux. Si vous ne pouvez pas supposer que les variances sont égales, utilisez la méthode ANOVA de Welch, qui est une option d'ANOVA à un facteur contrôlé disponible dans Minitab Statistical Software.