Sur ce thème
Etape 1 : Déterminer si l'association entre la réponse et le terme est statistiquement significative
- Valeur de p ≤ α : l'association est statistiquement significative.
- Si la valeur de p est inférieure ou égale au seuil de signification, vous pouvez conclure qu'il existe une association statistiquement significative entre la variable de réponse et le terme.
- Valeur de p > α : l'association n'est pas statistiquement significative.
- Si la valeur de p est supérieure au seuil de signification, vous ne pouvez pas conclure qu'il existe une association statistiquement significative entre la variable de réponse et le terme. Il est sans doute nécessaire de réajuster le modèle sans le terme.
- Si un facteur fixe est significatif, vous pouvez en conclure que les moyennes des niveaux ne sont pas toutes égales.
- Si un facteur aléatoire est significatif, vous pouvez en conclure qu'il contribue à la variation dans la réponse.
- Si un terme d'interaction est significatif, la relation entre l'un des facteurs et la réponse dépend des autres facteurs du terme. Dans ce cas, vous ne devez pas interpréter les effets principaux sans prendre en compte l'effet d'interaction.
- Si une covariable est statistiquement significative, vous pouvez en conclure qu'une variation de la valeur de la covariable entraîne une variation de la valeur de réponse moyenne.
- Si un terme polynomial est significatif, vous pouvez en conclure que les données contiennent une courbure.
Coefficients
| Terme | Coeff | Coef ErT | Valeur de T | Valeur de p | FIV |
|---|---|---|---|---|---|
| Constante | -4969 | 191 | -25,97 | 0,000 | |
| Température | 83,87 | 3,13 | 26,82 | 0,000 | 301,00 |
| TypeVerre | |||||
| 1 | 1323 | 271 | 4,89 | 0,000 | 3604,00 |
| 2 | 1554 | 271 | 5,74 | 0,000 | 3604,00 |
| Température*Température | -0,2852 | 0,0125 | -22,83 | 0,000 | 301,00 |
| Température*TypeVerre | |||||
| 1 | -24,40 | 4,42 | -5,52 | 0,000 | 15451,33 |
| 2 | -27,87 | 4,42 | -6,30 | 0,000 | 15451,33 |
| Température*Température*TypeVerre | |||||
| 1 | 0,1124 | 0,0177 | 6,36 | 0,000 | 4354,00 |
| 2 | 0,1220 | 0,0177 | 6,91 | 0,000 | 4354,00 |
Résultats principaux : valeur de p, coefficients
Dans ces résultats, les effets principaux du type de verre et de la température sont statistiquement significatifs à un seuil de signification de 0,05. Vous pouvez en conclure que la variation de ces variables entraîne une variation de la variable de réponse.
Les résultats affichent les coefficients pour deux des trois types de verre présents dans l'expérience. Par défaut, Minitab supprime un niveau de facteur pour éviter toute multicolinéarité parfaite. Etant donné que l'analyse utilise le schéma de codage −1, 0, +1, les coefficients des effets principaux représentent la différence entre chaque moyenne de niveau et la moyenne générale. Par exemple, le type de verre 1 est associé à une luminosité qui est supérieure à la moyenne générale de 1 323 unités.
La température est une covariable dans ce modèle. Le coefficient de l'effet principal représente la variation de la réponse moyenne lorsque la covariable augmente d'une unité et que tous les autres termes du modèle sont maintenus constants. Pour chaque augmentation d'un degré de la température, la luminosité moyenne augmente de 83,87 unités.
Le type de verre et la température sont inclus dans des termes d'ordre supérieur statistiquement significatifs.
Les termes d'interaction à deux ou trois facteurs pour le type de verre et la température sont statistiquement significatifs. Ces interactions indiquent que la relation entre chaque variable et la réponse dépend de la valeur de l'autre variable. Par exemple, l'effet du type de verre sur la luminosité dépend de la température.
Le terme polynomial Température*Température indique que la courbure décrite par la relation entre la température et la luminosité est statistiquement significative.
Vous ne devez pas interpréter les effets principaux sans prendre en compte les effets des interactions et la courbure. Pour mieux comprendre les effets principaux, les effets d'interaction et la courbure de votre modèle, reportez-vous aux rubriques Diagrammes factoriels et Optimisation des réponses.
Etape 2 : Déterminer l'ajustement du modèle à vos données
Pour déterminer l'ajustement du modèle aux données, étudiez les statistiques d'adéquation de l'ajustement dans le tableau Récapitulatif du modèle.
- S
-
Utilisez S pour évaluer la capacité du modèle à décrire la réponse. Utilisez S plutôt que les statistiques R2 pour comparer l'ajustement des modèles qui n'ont pas de constante.
S est mesuré en unités de la variable de réponse et représente la distance entre les valeurs de données et les valeurs ajustées. Plus S est petit, mieux le modèle décrit la réponse. Cependant, une faible valeur de S n'indique pas en soi que le modèle respecte les hypothèses du modèle. Vous devez examiner les graphiques des valeurs résiduelles pour vérifier les hypothèses.
- R carré
-
Plus la valeur R2 est élevée, plus le modèle est ajusté à vos données. R2 est toujours compris entre 0 et 100 %.
La valeur R2 augmente toujours lorsque vous ajoutez des prédicteurs à un modèle. Par exemple, le meilleur modèle à 5 prédicteurs aura toujours une valeur R2 au moins aussi élevée que celle du meilleur modèle à 4 prédicteurs. Par conséquent, R2 est surtout utile pour comparer des modèles de même taille.
- R carré (ajust)
-
Utilisez la valeur R2 ajusté pour comparer des modèles n'ayant pas le même nombre de prédicteurs. R2 augmente toujours lorsque vous ajoutez un prédicteur au modèle, même lorsque ce prédicteur n'apporte aucune amélioration réelle au modèle. La valeur de R2 ajusté intègre le nombre de prédicteurs dans le modèle pour vous aider à choisir le modèle correct.
- R carré (prév)
-
La valeur R2 prévu permet de déterminer la capacité de votre modèle à prévoir la réponse pour de nouvelles observations.Les modèles ayant des valeurs de R2 prévu élevées ont une meilleure capacité de prévision.
Une valeur de R2 prévu considérablement inférieure à R2 peut être un signe de surajustement du modèle. Un modèle est dit surajusté lorsqu'il inclut des termes pour des effets qui ne sont pas importants dans la population. Le modèle est alors spécialement ajusté aux données des échantillons, mais risque ne pas être utile pour effectuer des prévisions concernant la population entière.
La valeur R2 prévu peut également être plus utile que R2 ajusté pour comparer des modèles, car elle est calculée avec des observations qui ne sont pas incluses dans le calcul du modèle.
- AICc et BIC
- Lorsque vous affichez les détails de chaque étape d'une sélection pas à pas ou lorsque vous affichez les résultats développés de l'analyse, Minitab présente deux autres statistiques. Il s'agit du critère d'information d'Akaike corrigé (AICc) et du critère d'information bayésien (BIC). Ces statistiques vous permettent de comparer différents modèles. Des valeurs faibles sont souhaitables pour chacune. Minitab n'affiche pas ces statistiques et n'effectue pas de sélection pas à pas quand les données comportent des facteurs aléatoires.
-
Les petits échantillons ne fournissent pas d'estimation précise de la force de la relation entre la réponse et les prédicteurs. Par exemple, pour obtenir une valeur R2 plus précise, vous devez utiliser un échantillon plus grand (en général, 40 ou plus).
-
Les statistiques d'adéquation de l'ajustement ne sont qu'un des types de mesures permettant d'évaluer l'ajustement du modèle. Même si un modèle a une valeur souhaitable, vous devez consulter les graphiques des valeurs résiduelles pour vérifier que le modèle respecte les hypothèses.
Récapitulatif du modèle
| S | R carré | R carré (ajust) | R carré (prév) |
|---|---|---|---|
| 19,1185 | 99,73% | 99,61% | 99,39% |
Résultats principaux : S, R carré, R carré (ajust), R carré (prév)
Dans ces résultats, le modèle explique 99,73 % de la variation de la luminosité des échantillons de dalles de verre. Pour ces données, la valeur de R2 indique que le modèle fournit un ajustement aux données correct. Si des modèles supplémentaires sont ajustés avec d'autres prédicteurs, utilisez les valeurs de R2 ajusté et les valeurs de R2 prévu pour comparer l'ajustement des modèles aux données.
Etape 3 : Déterminer si votre modèle vérifie les hypothèses de l'analyse
Les graphiques des valeurs résiduelles permettent de déterminer si le modèle est adapté et si les hypothèses de l'analyse sont vérifiées. Si elles ne le sont pas, il se peut que le modèle ne soit pas ajusté aux données et vous devez être prudent lors de l'interprétation des résultats.
Pour plus d'informations sur la manière de traiter les schémas dans les graphiques des valeurs résiduelles, reportez-vous à la rubrique Diagrammes de valeurs résiduelles pour la fonction Ajuster le modèle linéaire général et cliquez sur le nom du graphique des valeurs résiduelles dans la liste située en haut de la page.
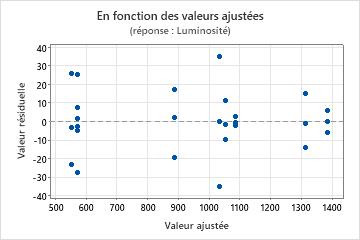
Graphique des valeurs résiduelles en fonction des valeurs ajustées
Utilisez le diagramme des valeurs résiduelles en fonction des valeurs ajustées pour vérifier l'hypothèse selon laquelle les valeurs résiduelles suivent une loi normale et ont une variance constante. Dans l'idéal, les points doivent être répartis aléatoirement des deux côtés de 0, sans schéma reconnaissable.
| Schéma | Ce que le schéma indique |
|---|---|
| Eparpillement ou répartition déséquilibrée des valeurs résiduelles en fonction des valeurs ajustées | Variance non constante |
| Curviligne | Un terme d'ordre supérieur manquant |
| Un point très éloigné de zéro | Une valeur aberrante |
| Un point éloigné des autres points dans le sens des x | Un point influent |
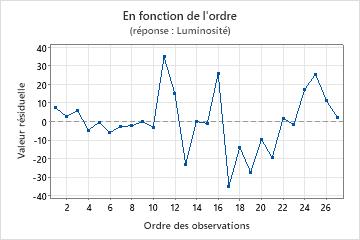
Graphique des valeurs résiduelles en fonction de l'ordre
Tendance
Equipe
Cycle
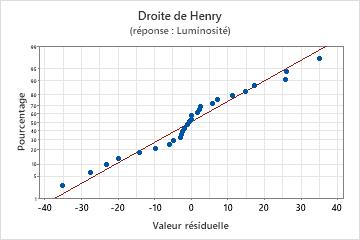
Droite de Henry des valeurs résiduelles
Utilisez la droite de Henry des valeurs résiduelles afin de vérifier l'hypothèse selon laquelle les valeurs résiduelles sont normalement distribuées. La droite de Henry des valeurs résiduelles doit suivre approximativement une ligne droite.
| Schéma | Ce que le schéma indique |
|---|---|
| Une ligne qui n'est pas droite | Non-normalité |
| Un point éloigné de la ligne | Une valeur aberrante |
| Une modification de la pente | Une variable non identifiée |