S
S représente l'écart type entre les valeurs de données et les valeurs ajustées. S est mesuré dans les unités de la réponse.
Interprétation
Utilisez S pour évaluer la capacité du modèle à décrire la réponse. S est mesuré en unités de la variable de réponse et représente la distance entre les valeurs de données et les valeurs ajustées. Plus S est petit, mieux le modèle décrit la réponse. Cependant, une faible valeur de S n'indique pas en soi que le modèle respecte les hypothèses du modèle. Vous devez examiner les graphiques des valeurs résiduelles pour vérifier les hypothèses.
Par exemple, vous travaillez pour un fabricant de pommes chips qui étudie les facteurs jouant sur le pourcentage de chips brisées par conteneur. Vous réduisez le modèle jusqu'à ne conserver que les prédicteurs significatifs, et vous constatez que S a pour valeur 1,79. Ce résultat indique que l'écart type des points de données autour des valeurs ajustées est 1,79. Si vous comparez des modèles, les valeurs inférieures à 1,79 indiquent un meilleur ajustement, tandis que les valeurs supérieures indiquent un moins bon ajustement.
R carré
R2 représente le pourcentage de variation de la réponse expliqué par le modèle. Cette valeur est calculée comme 1 moins le rapport de la somme des carrés de l'erreur (variation non expliquée par le modèle) sur la somme totale des carrés (variation totale du modèle).
Interprétation
Utilisez la valeur R2 pour déterminer l'ajustement du modèle à vos données. Plus la valeur R2 est élevée, plus le modèle est ajusté à vos données. R2 est toujours compris entre 0 et 100 %.
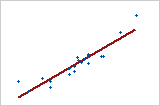
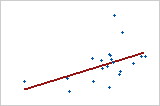
-
La valeur R2 augmente toujours lorsque vous ajoutez des prédicteurs à un modèle. Par exemple, le meilleur modèle à 5 prédicteurs aura toujours une valeur R2 au moins aussi élevée que celle du meilleur modèle à 4 prédicteurs. Par conséquent, R2 est surtout utile pour comparer des modèles de même taille.
-
Les petits échantillons ne fournissent pas d'estimation précise de la force de la relation entre la réponse et les prédicteurs. Par exemple, pour obtenir une valeur R2 plus précise, vous devez utiliser un échantillon plus grand (en général, 40 ou plus).
-
Les statistiques d'adéquation de l'ajustement ne sont qu'un des types de mesures permettant d'évaluer l'ajustement du modèle. Même si un modèle a une valeur souhaitable, vous devez consulter les graphiques des valeurs résiduelles pour vérifier que le modèle respecte les hypothèses.
R carré (ajust)
Le R2 ajusté est le pourcentage de la variation de la réponse qui est expliqué par le modèle, ajusté au nombre de prédicteurs du modèle par rapport au nombre d'observations. Le R2 ajusté est égal à 1 moins le rapport entre le carré moyen de l'erreur (CME) et le carré moyen total (CM Total).
Interprétation
Utilisez la valeur R2 ajusté pour comparer des modèles n'ayant pas le même nombre de prédicteurs. R2 augmente toujours lorsque vous ajoutez un prédicteur au modèle, même lorsque ce prédicteur n'apporte aucune amélioration réelle au modèle. La valeur de R2 ajusté intègre le nombre de prédicteurs dans le modèle pour vous aider à choisir le modèle correct.
| Modèle | % de pomme de terre | Vitesse de refroidissement | Température de cuisson | R2 | R2 ajusté |
|---|---|---|---|---|---|
| 1 | X | (-52@, 0@, +1) | (-51@, 0@, +1) | ||
| 2 | X | X | (-63@, 0@, +1) | (-62@, 0@, +1) | |
| 3 | X | X | X | (-65@, 0@, +1) | (-62@, 0@, +1) |
Le premier modèle présente une valeur de R2 de plus de 50 %. Le deuxième modèle ajoute la vitesse de refroidissement au modèle. La valeur R2 ajusté augmente, ce qui indique que la vitesse de refroidissement améliore le modèle. Le troisième modèle, qui inclut la température de cuisson, augmente la valeur R2 mais pas la valeur R2 ajusté. Ces résultats indiquent que la température de cuisson n'améliore pas le modèle. Selon ces résultats, vous devriez supprimer la température de cuisson du modèle.
SomCar-ErrPrév
La somme des carrés de l'erreur de prévision (SomCar-ErrPrév) permet de mesurer l'écart entre les valeurs ajustées et les valeurs observées. La SomCar-ErrPrév est semblable à la somme des carrés de l'erreur résiduelle (SCE), qui est la somme des carrés des valeurs résiduelles. Toutefois, la SomCar-ErrPrév utilise une autre méthode de calcul pour les valeurs résiduelles. La formule utilisée pour calculer la SomCar-ErrPrév revient à supprimer systématiquement chaque observation de l'ensemble de données, à estimer l'équation de régression et à évaluer la capacité du modèle à prévoir l'observation supprimée.
Interprétation
Vous pouvez utiliser SomCar-ErrPrév afin d'évaluer la capacité de prévision de votre modèle. En général, plus la valeur SomCar-ErrPrév est petite, meilleure est la capacité de prévision du modèle. Minitab utilise la valeur SomCar-ErrPrév pour calculer le R2 prévu, dont l'interprétation est généralement plus intuitive. L'ensemble de ces statistiques permet d'éviter le surajustement du modèle. Un modèle est dit surajusté lorsqu'il inclut des termes pour des effets qui ne sont pas importants dans la population, bien qu'ils semblent importants dans les données échantillons. Le modèle est alors spécialement ajusté aux données des échantillons, mais risque ne pas être utile pour effectuer des prévisions concernant la population entière.
R carré (prév)
Le calcul du R2 prévu utilise une formule qui revient à supprimer systématiquement chaque observation de l'ensemble de données, à estimer l'équation de régression et à évaluer la capacité du modèle à prévoir l'observation supprimée. La valeur du R2 prévu est comprise entre 0 et 100 %. Minitab affiche zéro lorsque les calculs de R2 prévu génèrent des valeurs négatives.
Interprétation
La valeur R2 prévu permet de déterminer la capacité de votre modèle à prévoir la réponse pour de nouvelles observations. Les modèles ayant des valeurs de R2 prévu élevées ont une meilleure capacité de prévision.
Une valeur de R2 prévu considérablement inférieure à R2 peut être un signe de surajustement du modèle. Un modèle est dit surajusté lorsqu'il inclut des termes pour des effets qui ne sont pas importants dans la population. Le modèle est alors spécialement ajusté aux données des échantillons, mais risque ne pas être utile pour effectuer des prévisions concernant la population entière.
La valeur R2 prévu peut également être plus utile que R2 ajusté pour comparer des modèles, car elle est calculée avec des observations qui ne sont pas incluses dans le calcul du modèle.
Par exemple, un analyste travaillant pour une société de conseil financier met au point un modèle de prévision de la conjoncture. Le modèle semble prometteur, car il possède un R2 de 87 %. Toutefois, le R2 prévu n'atteint que 52 %, ce qui indique que le modèle est peut-être surajusté.
AICc et BIC
Le critère d'information d'Akaike corrigé (AICc) et le critère d'information bayésien (BIC) sont des mesures de la qualité relative d'un modèle qui rend compte de l'ajustement du modèle et du nombre de termes qu'il contient.
Interprétation
Utilisez l'AICc et le BIC pour comparer différents modèles. Les valeurs faibles sont les valeurs souhaitables. Cependant, le modèle ayant les valeurs les plus faibles pour un ensemble de prédicteurs n'est pas forcément bien ajusté aux données. Vous devez aussi utiliser les tests et les graphiques des valeurs résiduelles pour évaluer l'ajustement du modèle aux données.
Les valeurs AICc et BIC évaluent toutes deux la probabilité du modèle, puis ajoutent une pénalité pour l'ajout de termes. Cette pénalité réduit la tendance du système à surajuster le modèle aux données échantillon. Cette réduction permet généralement de produire un modèle qui fonctionne mieux.
De manière générale, quand le nombre de paramètres est relativement faible par rapport à l'effectif d'échantillon, une plus grande pénalité est appliquée à la valeur BIC qu'à la valeur AICc pour l'ajout de chaque paramètre. Dans ce cas, le modèle qui fournit la plus faible valeur BIC tend à être plus petit que celui qui fournit la plus faible valeur AICc.
Dans certains cas courants, par exemple dans les plans de criblage, le nombre de paramètres est généralement élevé par rapport à l'effectif d'échantillon. Dans ce cas, le modèle qui fournit la plus faible valeur AICc tend à être plus petit que celui qui fournit la plus faible valeur BIC. Par exemple, pour un plan de criblage définitif à 13 essais, le modèle qui fournit la plus faible valeur AICc tend à être plus petit que celui qui fournit la plus faible valeur BIC parmi l'ensemble des modèles à 6 paramètres ou plus.
Pour plus d'informations sur les valeurs AICc et BIC, reportez-vous à Burnham et Anderson.1
Cp de Mallows
Le Cp de Mallows peut vous aider à choisir entre plusieurs modèles de régression. Le Cp de Mallows compare le modèle complet à ceux contenant les sous-ensembles de prédicteurs. Il vous permet de trouver un juste équilibre concernant le nombre de prédicteurs figurant dans le modèle. Un modèle possédant trop de prédicteurs peut s'avérer relativement imprécis, tandis qu'un modèle possédant trop peu de prédicteurs peut générer des estimations biaisées. Vous ne pouvez utiliser le Cp de Mallows pour comparer des modèles de régression que lorsque vous commencez avec le même ensemble complet de prédicteurs.
Interprétation
Une valeur du Cp de Mallows proche de la somme de la constante et du nombre de prédicteurs indique que le modèle génère des estimations relativement précises et non biaisées.
Une valeur du Cp de Mallows supérieure à la somme de la constante et du nombre de prédicteurs indique que le modèle est biaisé et qu'il n'est pas correctement ajusté aux données.