Sur ce thème
- A propos de la collecte de données en sous-groupes
- Comment les sous-groupes sont liés à la variation du procédé ?
- Estimer la variation entre les sous-groupes lorsqu'il est impossible de collecter des sous-groupes rationnels
- Comment l'effectif d'échantillon influe-t-il sur les estimations de la variation du procédé ?
- Comment définir des sous-groupes dans la feuille de travail
A propos de la collecte de données en sous-groupes
Vous pouvez utiliser des observations individuelles ou des données en sous-groupes pour une analyse de capabilité. Veillez à collecter les données sur un intervalle de temps suffisamment long pour identifier les différentes sources de variation du procédé.
Lorsque cela est possible, collectez des données en sous-groupes rationnels, qui sont de petits échantillons d'éléments similaires (en général de 3 à 5) qui sont produits pendant une courte période de temps. Les sous-groupes doivent être représentatifs des résultats du procédé que vous souhaitez évaluer. Les éléments de chaque sous-groupe sont collectés avec les mêmes variables d'entrée et dans les mêmes conditions, comme le personnel, l'équipement, les fournisseurs ou l'environnement. Par conséquent, lorsque vous estimez la variation au sein de ces petits sous-groupes, vous estimez la variation inhérente au procédé ou faisant naturellement partie de ce dernier.
Les sous-groupes doivent être collectés à intervalles proches dans le temps, mais demeurer néanmoins indépendants les uns des autres. Par exemple, une machine à découper produit 100 pièces de plastique à l'heure. Chaque heure, l'ingénieur qualité mesure cinq pièces sélectionnées de façon aléatoire. Chaque échantillon de cinq pièces est un sous-groupe.
Comment les sous-groupes sont liés à la variation du procédé ?
Il existe deux types de variations dans un procédé : la variation à l'intérieur des sous-groupes et la variation entre les sous-groupes. Pour améliorer la qualité du procédé, vous devez fournir un effort afin d'éliminer la variation entre les sous-groupes et de réduire la variation à l'intérieur des sous-groupes.
- Variation à l'intérieur des sous-groupes
- Variation entre les mesures à l'intérieur des sous-groupes, également appelée variation due aux causes communes.
- Variation entre les sous-groupes
- Variation entre les sous-groupes pouvant être causée par des facteurs identifiables spécifiques, ou causes spéciales.
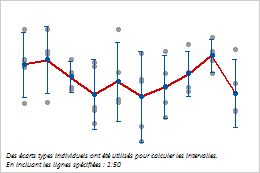
Variation à l'intérieur des sous-groupes et variation entre les sous-groupes
Ce diagramme de valeurs individuelles affiche les valeurs des échantillons prélevés de la machine à découpe. Chaque ligne verticale de points relevés représente les valeurs d'un sous-groupe. Les intervalles représentent la variation à l'intérieur des sous-groupes, tandis que la ligne de jonction de la moyenne représente la variation entre les sous-groupes.
Estimer la variation entre les sous-groupes lorsqu'il est impossible de collecter des sous-groupes rationnels
Il est parfois impossible ou peu pratique de collecter des sous-groupes rationnels de sorte que toutes les variations dues aux causes communes soient présentes dans chaque sous-groupe.
Par exemple, vous produisez un grand nombre de pièces à partir du même lot de matières premières. Si les échantillons pour chaque sous-groupe proviennent de lots séparés, la variation à l'intérieur des sous-groupes n'explique pas la variation entre lots. La variation entre les sous-groupes doit être estimée séparément. La variation entre les sous-groupes et la variation à l'intérieur des sous-groupes peuvent alors être combinées pour refléter l'effet total des variations dues aux causes communes.
Comment l'effectif d'échantillon influe-t-il sur les estimations de la variation du procédé ?
Pour les fonctions Analyse de capabilité normale et Analyse de capabilité utilisant une loi non normale, vous pouvez utiliser des sous-groupes de n'importe quel effectif, même des sous-groupes d'effectif 1. Vous pouvez également utiliser des sous-groupes d'effectif variable dans la même analyse.
La variation globale du procédé, telle que mesurée par l'écart type global, ne change pas pour les effectifs de sous-groupes variables, car son calcul dépend de l'effectif d'échantillon total, pas de l'effectif d'échantillon du sous-groupe.
Même lorsque l'effectif d'échantillon est 1, l'écart type à l'intérieur des sous-groupes et l'écart type global donnent lieu à des valeurs différentes. Toutefois, s'il existe une variation négligeable entre les sous-groupes, ces deux estimations sont approximativement égales.
Avec l'option Analyse de capabilité entre/à l'intérieur, vos effectifs de sous-groupes doivent répondre aux exigences suivantes.
- Effectif des sous-groupes > 1
- Lorsque l'effectif de sous-groupe est 1, la seule manière d'estimer l'écart type à l'intérieur des sous-groupes est d'utiliser des sous-groupes adjacents. Cette méthode est appropriée lorsque vous pouvez partir de l'hypothèse selon laquelle il n'existe pas de variation entre les sous-groupes, comme cela est généralement le cas pour une analyse de capabilité normale. Cependant, lorsqu'il est probable qu'il existe une variation significative entre les sous-groupes, il est nécessaire d'avoir au moins deux observations pour chaque sous-groupe, afin de calculer la variation à l'intérieur des sous-groupes et de réaliser une analyse de capabilité "entre/à l'intérieur".
- La plupart des sous-groupes doivent avoir le même effectif
- Pour calculer les écarts types "entre" et "entre/à l'intérieur", plus de la moitié des sous-groupes doivent avoir le même effectif.
Exemple d'exigences d'effectifs de sous-groupes variables
Supposons que vous ayez un sous-groupe d'effectif 5, un d'effectif 7 et un d'effectif 4. Chaque effectif de sous-groupe apparaît une fois pour un total de trois sous-groupes. Par conséquent, chaque effectif de sous-groupe apparaît le tiers du temps et aucun effectif de sous-groupe ne se présente plus de la moitié du temps. Vous devrez ajouter deux sous-groupes supplémentaires d'effectif 5 (par exemple) pour créer une situation dans laquelle un effectif de sous-groupe est utilisé pour plus de la moitié des sous-groupes.
Important
Si l'effectif de sous-groupe ne remplit pas ces exigences lorsque vous utilisez la fonction Analyse de capabilité entre/à l'intérieur, Minitab affiche les messages d'erreur suivants :
- * ERREUR * "Effectif de sous-groupe non valide. La valeur suivante est trop petite : "1". Veuillez préciser : une colonne ou une constante."
- * ERREUR * Plus de la moitié des sous-groupes doivent avoir la même taille."
Comment définir des sous-groupes dans la feuille de travail
Lorsque vous effectuez une analyse de capabilité, Minitab suppose que les données sont saisies dans la feuille de travail dans l'ordre chronologique. Par conséquent, les observations relatives au même sous-groupe doivent se trouver dans des lignes adjacentes. Une colonne d'ID de sous-groupes permet de définir les sous-groupes.
Par exemple, cette feuille de travail affiche des données pour 3 sous-groupes. Chaque sous-groupe dispose de 3 observations.
| Mesure | ID de sous-groupe |
|---|---|
| 0,9 | 1 |
| 1,2 | 1 |
| 1,3 | 1 |
| 1,7 | 2 |
| 1,2 | 2 |
| 1,5 | 2 |
| 1,5 | 3 |
| 1,2 | 3 |
| 1,2 | 3 |
Chaque fois qu'une valeur de la colonne d'ID de sous-groupes est modifiée, Minitab interprète la nouvelle valeur comme le début d'un sous-groupe distinct. Par conséquent, si les valeurs identiques d'une colonne d'ID de sous-groupes n'apparaissent pas dans des lignes adjacentes, Minitab les interprète comme des sous-groupes différents.
Par exemple, cette feuille de travail affiche des données pour 6 sous-groupes. Chaque sous-groupe dispose de 2 observations.
| Mesure | ID de sous-groupe | Date |
|---|---|---|
| 11,3 | 1 | 3/1 |
| 10,1 | 1 | 3/1 |
| 10,0 | 2 | 3/1 |
| 9,3 | 2 | 3/1 |
| 14,0 | 3 | 3/1 |
| 10,2 | 3 | 3/1 |
| 11,1 | 1 | 3/2 |
| 13,0 | 1 | 3/2 |
| 9,2 | 2 | 3/2 |
| 9,7 | 2 | 3/2 |
| 12,7 | 3 | 3/2 |
| 12/1 | 3 | 3/2 |
Les mêmes valeurs (1, 2, 3) sont utilisées dans les lignes non adjacentes de la colonne d'ID de sous-groupe. De ce fait, le sous-groupe 1 sur 3/1 est considéré comme distinct du sous-groupe 1 sur 3/2 ; le sous-groupe 2 sur 3/1 est considéré comme distinct du sous-groupe 2 sur 3/2, etc.
Comment déplacer des observations du même sous-groupe de lignes non adjacentes vers des lignes adjacentes
Si des ID de sous-groupes répétés dans des lignes non adjacentes renvoient à des mesures appartenant réellement au même sous-groupe, vous devez les déplacer dans des lignes adjacentes avant d'effectuer une analyse de capabilité. Pour ce faire, vous pouvez utiliser la commande SORT.
Par exemple, dans cette feuille de travail, des observations du même sous-groupe ont le même ID de sous-groupe (1, 2 ou 3) mais les observations ne se trouvent pas dans des lignes adjacentes.
| Mesure | ID de sous-groupe |
|---|---|
| 112,3 | 1 |
| 110,1 | 2 |
| 109,9 | 3 |
| 99,3 | 1 |
| 104,0 | 2 |
| 110,2 | 3 |
| 100,1 | 1 |
| 103,2 | 2 |
| 102,2 | 3 |
| 101,7 | 1 |
| 98,2 | 2 |
| 99,0 | 3 |
- Sélectionnez .
- Dans la zone Colonnes à trier par, dans Colonne, saisissez un ID de sous-groupe.
- Dans Colonnes à trier, sélectionnez Toutes les colonnes.
- Cliquez sur OK.
Les données de la feuille de travail apparaissent maintenant avec des ID de sous-groupes identiques dans des colonnes adjacentes. Lorsque vous effectuez une analyse de capabilité, toutes les observations possédant le même ID de sous-groupe sont analysées comme sous-groupe unique.
| Mesure triée | ID de sous-groupe trié |
|---|---|
| 112,3 | 1 |
| 99,3 | 1 |
| 100,1 | 1 |
| 101,7 | 1 |
| 110,1 | 2 |
| 104,0 | 2 |
| 103,2 | 2 |
| 98,2 | 2 |
| 109,9 | 3 |
| 110,2 | 3 |
| 102,2 | 3 |
| 99,0 | 3 |
Pour plus d'informations sur le tri des données, reportez-vous à la rubrique Comment Minitab trie-t-il les données ?.