Sur ce thème
LSI
La limite de spécification inférieure (LSI) du procédé est la valeur minimale autorisée pour le produit ou service. Cette limite n'indique pas les résultats réels du procédé, mais les résultats que vous souhaitez qu'il atteigne. Vous indiquez la LSI lorsque vous configurez l'analyse de capabilité.
Interprétation
Utilisez les limites LSI et LSS pour définir les exigences client et pour déterminer si votre procédé produit des éléments conformes à ces exigences.
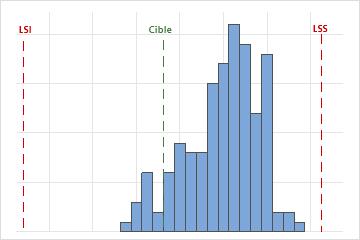
Les limites supérieures et inférieures des spécifications sont identifiées par les lignes pointillées verticales sur l’histogramme. Comparez les barres d’histogramme aux lignes pour évaluer si les mesures respectent les limites de la spécification.
La dispersion de spécification correspond à la distance entre la limite de spécification inférieure (LSI) et limite de spécification supérieure (LSS). Supposons qu’une entreprise produise des stylos à bille et que le diamètre extérieur cible de la bille soit de 0,35 mm. La plage acceptable pour les diamètres extérieurs de la bille est de 0,34 à 0,36 mm. Par conséquent, la LSL est de 0,34, la LSU est de 0,36 et l’écart de spécification est de 0,02 mm.
Minitab compare la dispersion de spécification à la dispersion du procédé pour déterminer la capabilité de celui-ci.
Cible
La cible est la valeur idéale d'un procédé, définie selon les exigences du client. Par exemple, si une pièce cylindrique offre des performances optimales dans un produit lorsque le diamètre est de 32 mm, la valeur de 32 mm correspond à la valeur cible pour cette pièce.
Interprétation
Utilisez la cible pour définir les exigences client et effectuer une comparaison avec vos observations.
La valeur cible est généralement (mais pas toujours) centrée entre les limites de spécification inférieure et supérieure. Lorsque vous avez une cible, regardez si votre procédé est centré près de la cible.
LSS
La limite de spécification supérieure (LSS) du procédé est la valeur maximale autorisée pour le produit ou service. Cette limite n'indique pas les résultats réels du procédé, mais les résultats que vous souhaitez qu'il atteigne. Vous indiquez la LSS lorsque vous configurez l'analyse de capabilité.
Interprétation
Utilisez les limites LSI et LSS pour définir les exigences client et pour déterminer si votre procédé produit des éléments conformes à ces exigences.
Les limites supérieures et inférieures des spécifications sont identifiées par les lignes pointillées verticales sur l’histogramme. Comparez les barres d’histogramme aux lignes pour évaluer si les mesures respectent les limites de la spécification.
La dispersion de spécification correspond à la distance entre la limite de spécification inférieure (LSI) et limite de spécification supérieure (LSS). Supposons qu’une entreprise produise des stylos à bille et que le diamètre extérieur cible de la bille soit de 0,35 mm. La plage acceptable pour les diamètres extérieurs de la bille est de 0,34 à 0,36 mm. Par conséquent, la LSL est de 0,34, la LSU est de 0,36 et l’écart de spécification est de 0,02 mm.
Minitab compare la dispersion de spécification à la dispersion du procédé pour déterminer la capabilité de celui-ci.
Médiane de l’échantillon
La médiane de l’échantillon est le point médian de l’ensemble de données. Ce point de milieu est celui qui sépare les observations en deux moitiés égales, l'une supérieure à la valeur, l'autre inférieure. La médiane est déterminée en classant les observations, puis en prenant l'observation de rang [N + 1] / 2 dans l'ordre obtenu. Si le nombre d'observations est pair, la médiane est égale à la moyenne des observations de rang N/2 et [N/2] + 1.
Interprétation
Utilisez l’échantillon médian pour estimer la valeur médiane de votre processus. Dans la plupart des données, la médiane est une bonne estimation des données typiques du processus. Habituellement, vous voulez que la médiane soit proche de la cible du processus.
Pour les données qui suivent une distribution symétrique en forme de cloche, la moyenne de l’échantillon est généralement une bonne estimation des données typiques du processus. Pour les données qui ne suivent pas une distribution symétrique en forme de cloche, la moyenne de l’échantillon est parfois éloignée des données typiques. La médiane de l’échantillon est une meilleure représentation des données typiques lorsque la moyenne est éloignée des données typiques.
Moyenne de l'échantillon
La moyenne de l’échantillon est la moyenne des mesures de l’échantillon.
Interprétation
Utilisez la moyenne de l'échantillon pour estimer la valeur moyenne de votre procédé. Habituellement, vous voulez que la moyenne soit proche de la cible du processus.
Pour les données qui suivent une distribution symétrique en forme de cloche, la moyenne de l’échantillon est généralement une bonne estimation des données typiques du processus. Pour les données qui ne suivent pas une distribution symétrique en forme de cloche, la moyenne de l’échantillon est parfois éloignée des données typiques. La médiane de l’échantillon est une meilleure représentation des données typiques lorsque la moyenne est éloignée des données typiques.
Ecart type de l'échantillon
L’écart type de l’échantillon est l’écart type de toutes les mesures et est une estimation de la variation globale du processus. Si vos données sont collectées correctement, l'écart type global collecte toutes les sources de variation systémique. Dans ce cas, il représente la variation réelle du procédé constatée par le client dans le temps.
Interprétation
L'écart type est la mesure la plus courante de la dispersion ou de la répartition des données par rapport à la moyenne. Un écart type d'échantillon supérieur indique que vos données sont réparties plus largement autour de la moyenne. Habituellement, le même processus est plus capable avec des écarts-types plus petits qu’avec un écart-type plus grand.
N de l'échantillon
L'effectif d'échantillon (N) correspond au nombre total d'observations dans les données. Par exemple, si vous avez collecté 20 sous-groupes d'effectif égal à 5, votre N de l'échantillon est de 100.
Interprétation
Utilisez N pour évaluer votre effectif d'échantillon.
En général, des effectifs d'échantillons plus grands produisent des estimations plus fiables de la capabilité de procédé. Certains experts recommandent au moins 100 observations totales pour une analyse de capabilité.