Sur ce thème
Histogramme
Un histogramme divise les valeurs des échantillons en plusieurs intervalles et représente l'effectif des valeurs contenues dans chaque intervalle par une barre.
Interprétation
50 rééchantillonnages
1 000 rééchantillonnages
La loi de distribution est généralement plus facile à déterminer avec davantage de rééchantillonnages. Par exemple, dans ces données, la loi de distribution est ambiguë pour 50 rééchantillonnages. Avec 1 000 rééchantillonnages, la forme est approximativement normale.
L'histogramme permet de visualiser les résultats du test de l'hypothèse. Minitab ajuste les données de sorte que le milieu des rééchantillonnages soit le même que celui de la moyenne hypothétisée. Pour un test unilatéral, une ligne de référence est tracée au niveau de la moyenne de l'échantillon d'origine. Pour un test bilatéral, une ligne de référence est tracée au niveau de la moyenne de l'échantillon d'origine et à la même distance de l'autre côté de la moyenne hypothétisée. La valeur de p est la proportion des moyennes d'échantillon plus extrêmes que les valeurs sur les lignes de référence. En d'autres termes, la valeur de p est la proportion des moyennes d'échantillon qui sont aussi extrêmes que votre échantillon d'origine lorsque que vous supposez que l'hypothèse nulle est vraie. Ces moyennes apparaissent en rouge sur l'histogramme.
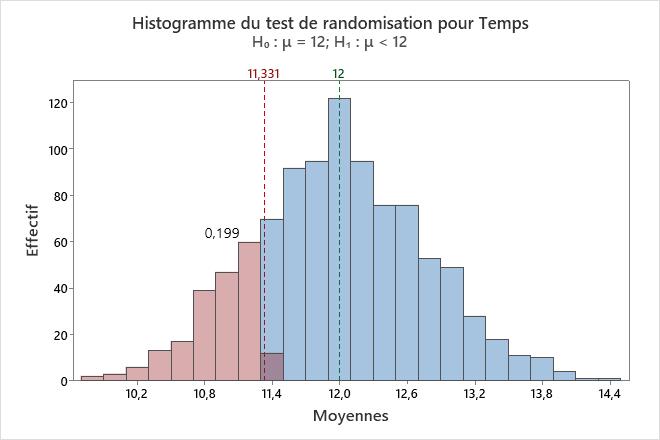
Sur cet histogramme, la distribution bootstrap semble normale. La valeur de p de 0,2030 indique que 20,3 % des moyennes d'échantillon sont inférieures à la moyenne de l'échantillon d'origine.
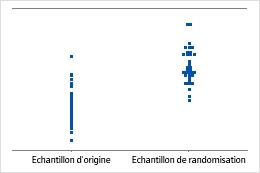
Diagramme des valeurs individuelles
Un diagramme des valeurs individuelles présente les valeurs individuelles contenues dans l'échantillon. Chaque cercle représente une observation. Un diagramme des valeurs individuelles est particulièrement utile lorsque vous disposez de relativement peu d'observations et que vous avez besoin d'évaluer l'effet de chacune d'entre elles.
Remarque
Minitab présente un diagramme des valeurs individuelles seulement lorsque vous effectuez un rééchantillonnage. Minitab présente les données d'origine et celles du rééchantillonnage.
Interprétation
Minitab ajuste les données de sorte que le milieu des rééchantillonnages soit le même que celui de la moyenne hypothétisée. Minitab calcule d'abord la différence entre la moyenne hypothétisée et la moyenne de l'échantillon d'origine. Ensuite, Minitab ajoute ou soustrait la différence à chaque valeur de l'échantillon d'origine. Des rééchantillonnages sont réalisés sur ces données ajustées.
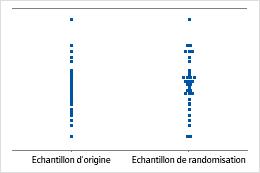
La moyenne de l'échantillon est égale à la moyenne hypothétisée
La moyenne de l'échantillon a 2 écarts types d'échantillon de moins que la moyenne hypothétisée
Hypothèse nulle et hypothèse alternative
- Hypothèse nulle
- L'hypothèse nulle affirme qu'un paramètre de la population (la moyenne, l'écart type, etc.) est égal à une valeur hypothétisée. L'hypothèse nulle est souvent une déclaration initiale basée sur des analyses précédentes ou des connaissances spécialisées.
- Hypothèse alternative
- L'hypothèse alternative affirme qu'un paramètre de la population est plus petit, plus grand ou différent de la valeur hypothétisée dans l'hypothèse nulle. L'hypothèse alternative est celle que vous pensez être vraie ou que vous espérez démontrer.
Interprétation
Dans les résultats, les hypothèses nulle et alternative vous permettent de vérifier que vous avez saisi une valeur correcte pour la moyenne hypothétisée.
Echantillon observé
| Variable | N | Moyenne | EcTyp | Variance | Somme | Minimum | Médiane | Maximum |
|---|---|---|---|---|---|---|---|---|
| Temps | 16 | 11,331 | 3,115 | 9,702 | 181,300 | 7,700 | 10,050 | 16,000 |
Test de randomisation
| Hypothèse nulle | H₀ : μ = 12 |
|---|---|
| Hypothèse alternative | H₁ : μ < 12 |
| Nombre de rééchantillonnages | Moyenne | EcTyp | Valeur de P |
|---|---|---|---|
| 1000 | 11,9783 | 0,7625 | 0,199 |
Dans ces résultats, l'hypothèse nulle est la suivante : la moyenne de population est égale à 12. L'hypothèse alternative stipule quant à elle que la moyenne est inférieure à 12.
Nombre de rééchantillonnages
Le nombre de rééchantillonnages est le nombre de fois que Minitab prélève un échantillon aléatoire avec remise dans votre ensemble de données d'origine. Généralement, un grand nombre de rééchantillonnages donne de meilleurs résultats.
Minitab ajuste les données de sorte que le milieu des rééchantillonnages soit le même que celui de la moyenne hypothétisée. Minitab calcule d'abord la différence entre la moyenne hypothétisée et la moyenne de l'échantillon d'origine. Ensuite, Minitab ajoute ou soustrait la différence à chaque valeur de l'échantillon d'origine. Des rééchantillonnages sont effectués sur ces données ajustées. L'effectif d'échantillon pour chaque rééchantillonnage est égal à l'effectif d'échantillon du fichier de données d'origine. Le nombre de rééchantillonnages est égal au nombre d'observations sur l'histogramme.
Moyenne
La moyenne est la somme de toutes les moyennes de l'échantillon bootstrap divisée par le nombre de rééchantillonnages. Minitab ajuste les données de sorte que le milieu des rééchantillonnages soit le même que celui de la moyenne hypothétisée.
Interprétation
Minitab affiche deux valeurs moyennes différentes : la moyenne de l'échantillon observé et celle de la distribution bootstrap. La moyenne de l'échantillon observé est une estimation de la moyenne de la population. La moyenne de la distribution bootstrap est généralement proche de la moyenne hypothétisée. Plus la différence entre ces deux valeurs est importante, plus vous avez de preuves par rapport à l'hypothèse nulle.
EcTyp (échantillon bootstrap)
L'écart type est la mesure la plus courante de la dispersion ou de la répartition des données sur la moyenne. Le symbole σ (sigma) est souvent utilisé pour représenter l'écart type d'une population, tandis que s sert à représenter l'écart type d'un échantillon. Une variation qui est aléatoire ou naturelle pour un procédé est souvent appelée un bruit. Etant donné que l'écart type utilise les mêmes unités que les données, il est généralement plus facile à interpréter que la variance.
L'écart type des échantillons bootstrap (également appelé erreur bootstrap type) est une estimation de l'écart type de la loi de distribution d'échantillonnage de la moyenne. L'erreur bootstrap type étant la variation des moyennes de l'échantillon, contrairement à l'écart type des échantillons observés qui représente la variation des observations individuelles, l'erreur bootstrap type est plus petite.
Interprétation
Utilisez l'écart type pour déterminer la dispersion des moyennes de l'échantillon bootstrap choisies parmi la moyenne globale. Une valeur d'écart type élevée indique une dispersion plus importante parmi les moyennes. D'une manière générale, pour une loi normale, environ 68 % des valeurs se situent dans un écart type de la moyenne globale, 95 % des valeurs se situent dans deux écarts types et 99,7 % des valeurs se situent dans trois écarts types.
Utilisez l'écart type des échantillons bootstrap pour estimer la précision des moyennes bootstrap. Une valeur plus faible indique une précision plus élevée. Généralement, un écart type plus important dans l'échantillon d'origine entraîne une erreur bootstrap type plus importante et un test d'hypothèse moins efficace. Un effectif d'échantillon plus petit entraîne également une erreur bootstrap type plus importante et un test d'hypothèse moins efficace.
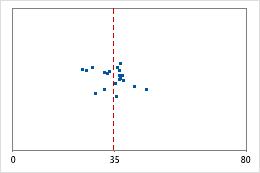
Hôpital 1
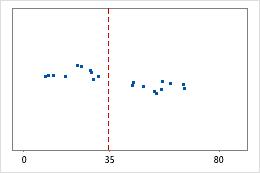
Hôpital 2
Durée jusqu'à la sortie de l'hôpital
Les administrateurs de deux hôpitaux étudient le temps que passent les patients dans le service des urgences de leurs établissements jusqu'à leur sortie. Bien que ces durées moyennes soient pratiquement identiques (35 minutes), les écarts types diffèrent de manière significative. L'écart type pour l'hôpital 1 est d'environ 6. En moyenne, la durée qui s'écoule jusqu'à la sortie d'un patient présente un écart d'environ 6 minutes par rapport à la moyenne (ligne bleue). L'écart type pour l'hôpital 2 est d'environ 20. En moyenne, la durée qui s'écoule jusqu'à la sortie d'un patient présente un écart d'environ 20 minutes par rapport à la moyenne (ligne bleue).
Valeur de p
La valeur de p est la proportion des moyennes d'échantillons qui sont aussi extrêmes que votre échantillon d'origine lorsque vous supposez que l'hypothèse nulle est vraie. Une valeur de p inférieure permet d'invalider l'hypothèse nulle avec plus de certitude.
Interprétation
Utilisez la valeur de p pour déterminer si la moyenne de la population est statistiquement différente de la moyenne hypothétisée.
- Valeur de p ≤ α : la différence entre les moyennes est statistiquement significative (Rejeter H0)
- Si la valeur de p est inférieure ou égale au seuil de signification, vous rejetez l'hypothèse nulle. Vous pouvez conclure que la différence entre la moyenne de la population et la moyenne hypothétisée est statistiquement significative. Pour calculer un intervalle de confiance et déterminer si cette différence est significative d'un point de vue pratique, utilisez la fonction Bootstrap pour un test de fonction à 1 échantillon. Pour plus d'informations, reportez-vous à la rubrique Signification statistique et pratique.
- Valeur de p > α : la différence entre les moyennes n'est pas statistiquement significative (Impossible de rejeter H0)
- Si la valeur de p est supérieure au seuil de signification, vous ne pouvez pas rejeter l'hypothèse nulle. Vous n'êtes pas en mesure de conclure que la différence entre la moyenne de la population et la moyenne hypothétisée est statistiquement significative.