In This Topic
Power for difference
The first line of output indicates how the hypotheses are specified for the equivalence test.
"Power for difference" indicates that the hypotheses are specified in terms of the difference between the mean of the test population and the mean of the reference population (Test mean – reference mean).
Power for ratio
The first line of output indicates how the hypotheses are specified for the equivalence test.
"Power for ratio" indicates that the hypotheses are specified in terms of the ratio between the mean of the test population and the mean of the reference population by log transformation (Test mean / reference mean).
Null hypothesis and alternative hypothesis
- Null hypothesis
- Minitab tests one or both of the following null hypotheses, depending on the alternative hypothesis that you selected:
- The difference (or ratio) between the mean of the test population and the mean of the reference population is greater than or equal to the upper equivalence limit.
- The difference (or ratio) between the mean of the test population and the mean of the reference population is less than or equal to the lower equivalence limit.
- Alternative hypothesis
- The alternative hypothesis states one or both of the following:
- The difference (or ratio) between the mean of the test population and the mean of the reference population is less than the upper equivalence limit.
- The difference (or ratio) between the mean of the test population and the mean of the reference population is greater than the lower equivalence limit.
Interpretation
Use the null and alternative hypotheses to verify that the equivalence criteria are correct and that you have selected the appropriate alternative hypothesis to test.
Method
| Power for difference: | Test mean - reference mean |
|---|---|
| Null hypothesis: | Difference ≤ -0.5 or Difference ≥ 0.5 |
| Alternative hypothesis: | -0.5 < Difference < 0.5 |
| α level: | 0.05 |
- The difference between the mean of the test population and the mean of the reference population is less than or equal to the lower equivalence limit of −0.5
- The difference between the mean of the test population and the mean of the reference population is greater than or equal to the upper equivalence limit of 0.5
α (alpha)
The significance level (denoted by alpha or α) is the maximum acceptable level of risk for rejecting the null hypothesis when the null hypothesis is true (type I error). For example, if you perform an equivalence test using the default hypotheses, an α of 0.05 indicates a 5% risk of claiming equivalence when the difference between the test mean and the reference mean does not actually fall within the equivalence limits.
The α-level for an equivalence test also determines the confidence level for the confidence interval. The confidence level is (1 – α) x 100% by default. If you use the alternative method of calculating the confidence interval, the confidence level is (1 – 2α) x 100%.
Interpretation
Use the significance level to minimize the power value of the test when the null hypothesis (H0) is true. Higher values for the significance level give the test more power, but also increase the chance of making a type I error, which is rejecting the null hypothesis when it is true.
Assumed standard deviation
The standard deviation of the differences is a measure of dispersion, or how much the paired differences vary relative to the mean of the paired differences. Variation that is random or natural to a process is often referred to as noise.
Interpretation
The assumed standard deviation is an estimate of the population standard deviation that you enter for the power analysis. Minitab uses the assumed standard deviation to calculate the power of the test. Higher values of the standard deviation indicate more variation or "noise" in the data, which decreases the statistical power of a test.
Difference
This value represents the difference between the mean of the test population and the mean of the reference population.
Note
The definitions and interpretation in this topic apply to a standard equivalence test that uses the default alternative hypothesis (Lower limit < test mean - reference mean < upper limit).
Interpretation
If you enter the sample size and the power of the test, then Minitab calculates the difference that the test can accommodate at the specified power and sample size. For larger sample sizes, the difference can be closer to your equivalence limits.
To more fully investigate the relationship between the sample size and the difference that the test can accommodate at a given power, use the power curve.
Method
| Power for difference: | Test mean - reference mean |
|---|---|
| Null hypothesis: | Difference ≤ -0.5 or Difference ≥ 0.5 |
| Alternative hypothesis: | -0.5 < Difference < 0.5 |
| α level: | 0.05 |
Results
| Sample Size | Power | Difference |
|---|---|---|
| 10 | 0.9 | -0.068351 |
| 10 | 0.9 | 0.068351 |
| 15 | 0.9 | -0.165953 |
| 15 | 0.9 | 0.165953 |
| 20 | 0.9 | -0.214756 |
| 20 | 0.9 | 0.214756 |
These results show how increasing the sample size increases the size of the difference that can be accommodated at a given power level:
- With 10 pairs of observations, the power of the test is at least 0.9 when the difference is between approximately −0.07 and 0.07.
- With 15 pairs of observations, the power of the test is at least 0.9 when the difference is between approximately −0.17 and 0.17.
- With 20 pairs of observations, the power of the test is at least 0.9 when the difference is between approximately −0.21 and 0.21.
Ratio
This value represents the ratio of the mean of the test population to the mean of the reference population. To perform power calculations for a ratio you must select a hypothesis about Test mean / reference mean (Ratio, by log transformation).
Note
The definitions and interpretation in this topic apply to an equivalence test that uses the default alternative hypothesis for the ratio (Lower limit < test mean / reference mean < upper limit).
Interpretation
If you enter the sample size and the power of the test, then Minitab calculates the minimum and maximum ratios that the test can accommodate at the specified power and sample size. For larger sample sizes, the ratio can be closer to your equivalence limits.
To more fully investigate the relationship between the sample size and the ratios that the test can accommodate at a given power, use the power curve.
Method
| Power for ratio: | Test mean / reference mean |
|---|---|
| Null hypothesis: | Ratio ≤ 0.9 or Ratio ≥ 1.1 |
| Alternative hypothesis: | 0.9 < Ratio < 1.1 |
| α level: | 0.05 |
Results
| Sample Size | Power | Ratio |
|---|---|---|
| 10 | 0.9 | 0.97588 |
| 10 | 0.9 | 1.01447 |
| 30 | 0.9 | 0.94028 |
| 30 | 0.9 | 1.05288 |
| 50 | 0.9 | 0.93073 |
| 50 | 0.9 | 1.06368 |
For example, the following results show how increasing the sample size increases the range of ratios that the test can accommodate at a given power level:
- With 10 pairs of observations, the power of the test is at least 0.9 when the ratio is between approximately 0.98 and 1.01.
- With 30 pairs of observations, the power of the test is at least 0.9 when the ratio is between approximately 0.94 and 1.05.
- With 50 pairs of observations, the power of the test is at least 0.9 when the ratio is between approximately 0.93 and 1.06.
Sample Size
The sample size is the total number of observations in the sample.
Interpretation
Use the sample size to estimate how many observations you need to obtain a certain power value for the equivalence test at a specific difference.
If you enter a difference (or ratio) and a power value for the test, then Minitab calculates how large your sample must be. Because sample sizes are whole numbers, the actual power of the test might be slightly greater than the power value that you specify.
If you increase the sample size, the power of the test also increases. You want enough observations in your sample to achieve adequate power. But you don't want a sample size so large that you waste time and money on unnecessary sampling or detect unimportant differences to be statistically significant.
To more fully investigate the relationship between the sample size and the difference (or ratio) that the test can accommodate at a given power, use the power curve.
Method
| Power for difference: | Test mean - reference mean |
|---|---|
| Null hypothesis: | Difference ≤ -0.5 or Difference ≥ 0.5 |
| Alternative hypothesis: | -0.5 < Difference < 0.5 |
| α level: | 0.05 |
Results
| Difference | Sample Size | Target Power | Actual Power |
|---|---|---|---|
| 0.0 | 10 | 0.9 | 0.930853 |
| 0.1 | 12 | 0.9 | 0.923863 |
| 0.2 | 19 | 0.9 | 0.911237 |
| 0.3 | 40 | 0.9 | 0.905568 |
| 0.4 | 153 | 0.9 | 0.900966 |
These results show that, as the size of the difference increases and approaches the value of the equivalence limit, a larger sample size is needed to achieve a given power. If the difference is 0, then you need 10 pairs of observations to achieve a power of 0.9. If the difference is 0.4, then you need at least 153 pairs of observations to achieve a power of 0.9.
Power
The power of an equivalence test is the probability that the test will demonstrate that the difference is within your equivalence limits, when it actually is. The power of an equivalence test is affected by the sample size, the difference, the equivalence limits, the variability of the data, and the significance level of the test.
For more information, go to Power for equivalence tests.
Interpretation
If you enter a sample size and a difference (or ratio), then Minitab calculates the power of the test. A power value of at least 0.9 is usually considered adequate. A power of 0.9 indicates that you have a 90% chance of demonstrating equivalence when the difference (or ratio) between the population means is actually within the equivalence limits. If an equivalence test has low power, you might fail to demonstrate equivalence even when the test mean and the reference mean are equivalent.
Usually, when the sample size is smaller or when the difference (or ratio) is closer to an equivalence limit, the test has less power to claim equivalence.
Method
| Power for difference: | Test mean - reference mean |
|---|---|
| Null hypothesis: | Difference ≤ -0.5 or Difference ≥ 0.5 |
| Alternative hypothesis: | -0.5 < Difference < 0.5 |
| α level: | 0.05 |
Results
| Difference | Sample Size | Power |
|---|---|---|
| 0.1 | 8 | 0.756885 |
| 0.1 | 15 | 0.968213 |
| 0.2 | 8 | 0.564674 |
| 0.2 | 15 | 0.837476 |
| 0.3 | 8 | 0.333618 |
| 0.3 | 15 | 0.543547 |
In these results, a sample size of 15 provides a power of approximately 0.97 when the difference is 0.1. However, the same sample size provides a power of 0.84 when the difference is 0.2, and a power of 0.54 when the difference is 0.3. At each difference value, increasing the sample size increases the power of the test.
Power curve
The power curve plots the power of the test versus the difference between the test mean and the reference mean.
Interpretation
Use the power curve to assess the appropriate sample size or power for your test.
The power curve represents every combination of power and difference (or ratio) for each sample size when the significance level and the standard deviation (or coefficient of variation) are held constant. Each symbol on the power curve represents a calculated value based on the values that you enter. For example, if you enter a sample size and a power value, Minitab calculates the corresponding difference (or ratio) and displays the calculated value on the graph.
Examine the values on the curve to determine the difference (or ratio) between the test mean and the reference mean that can be accommodated at a certain power value and sample size. A power value of 0.9 is usually considered adequate. However, some practitioners consider a power value of 0.8 to be adequate. If an equivalence test has low power, you might fail to demonstrate equivalence even when the population means are equivalent. If you increase the sample size, the power of the test also increases. You want enough observations in your sample to achieve adequate power. But you don't want a sample size so large that you waste time and money on unnecessary sampling or detect unimportant differences to be statistically significant. Usually, differences (or ratios) that are closer to the equivalence limits require more power to demonstrate equivalence.
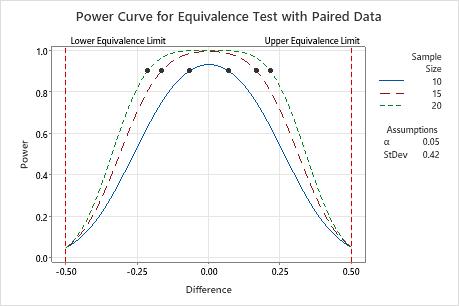
In this graph, the power curve for a sample size of 10 shows that the test has power of 0.9 for a difference of approximately ±0.1. The power curve for a sample size of 20 shows that the test has a power of 0.9 for a difference of approximately ±0.2. For each curve, as the difference approaches the lower equivalence limit or upper equivalence limit, the power of the test decreases and approaches α (alpha, which is the risk of claiming equivalence when it is not true).