In This Topic
Cp
- The specification spread (USL – LSL)
- The spread of the process (the 6-σ variation) based on the within-subgroup standard deviation
Interpretation
Use Cp to evaluate the potential capability of your process based on the process spread. Potential capability indicates the capability that could be achieved if process shifts and drifts were eliminated.
Because Cp does not consider the location of the process, it indicates the potential capability that your process could achieve if it were centered. Generally, higher Cp values indicate a more capable process. Lower Cp values indicate that your process may need improvement.
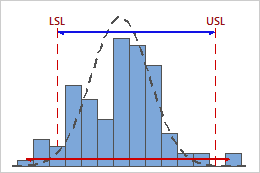
Low Cp
In this example, the specification spread is less than the within-subgroup process spread. Therefore, Cp is low (0.80), and the potential capability of the process is poor based on its variability.
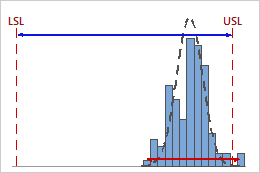
High Cp
In this example, the specification spread is considerably greater than the within-subgroup process spread. Therefore, Cp is high (2.76), and the potential capability of the process is good based on its variability.
-
Compare Cp to a benchmark value to assess the potential capability of your process. Many industries use a benchmark value of 1.33. If Cp is lower than your benchmark, consider how to improve your process by reducing its variation.
-
Compare Cp and Cpk. If Cp and Cpk are approximately equal, then the process is centered between the specification limits. If Cp and Cpk differ, then the process is not centered.
Caution
Because the Cp index does not consider the process location, it does not indicate how close the process is to the target region that is defined by the specification limits. For example, the following graphs show two processes with the same Cp value, yet one process falls within the specification limits and the other does not.
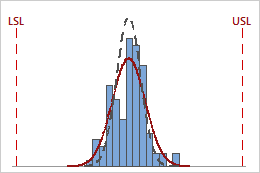
Cp = 3.13
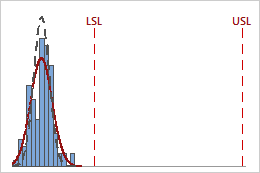
Cp = 3.13
For a complete and accurate analysis, use graphs in combination with other capability indices (such as Cpk) to draw meaningful conclusions from your data.
CPL
- The distance from the process mean to the lower specification limit (LSL)
- The one-sided spread of the process (the 3-σ variation) based on the within-subgroup standard deviation
Interpretation
Use CPL to evaluate the potential capability of your process relative to its lower specification limit. Potential capability indicates the capability that could be achieved if process shifts and drifts were eliminated.
Generally, higher CPL values indicate that the process is capable at the lower tail of its distribution. Lower CPL values indicate that your process may need improvement.
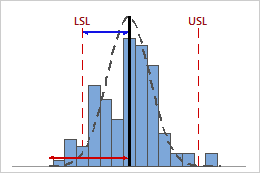
Low CPL
In this example, the distance from the process mean to the lower specification limit (LSL) is less than the one-sided process spread. Therefore, CPL is low (0.81), and the potential capability of the process is poor in relation to its lower specification limit.
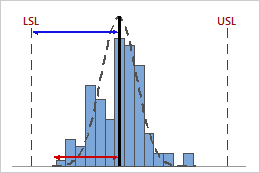
High CPL
In this example, the distance from the process mean to the lower specification limit (LSL) is greater than the one-sided process spread. Therefore, CPL is high (1.64), and the potential capability of the process is good in relation to its lower specification limit.
-
Compare CPL with a benchmark value to assess the potential capability of your process. Many industries use a benchmark value of 1.33. If CPL is lower than your benchmark, consider ways to improve your process, such as reducing its variation or shifting its location.
-
If you have both lower and upper specification limits, compare CPL with CPU. If CPL does not approximately equal CPU, the process is not centered.
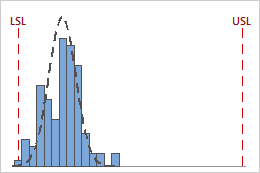
CPL = 0.92, CPU = 4.37
When CPL < CPU, the process is more likely to produce defective units that violate the lower specification limit.
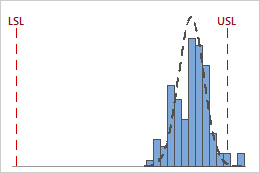
CPL = 4.37, CPU = 0.92
When CPU < CPL, the process is more likely to produce defective units that violate the upper specification limit.
CPU
- The distance from the process mean to the upper specification limit (USL)
- The one-sided spread of the process (the 3-σ variation) based on the variation within the subgroups
Interpretation
Use CPU to evaluate the potential capability of your process relative to its upper specification limit. Potential capability indicates the capability that could be achieved if process shifts and drifts were eliminated.
Generally, higher CPU values indicate that the process is capable at the upper tail of its distribution. Lower CPU values indicate that your process may need improvement.
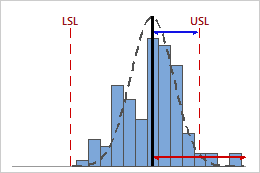
Low CPU
In this example, the distance from the process mean to the upper specification limit (USL) is less than the one-sided process spread. Therefore, CPU is low (0.96), and the potential capability of the process is poor in relation to its upper specification limit.
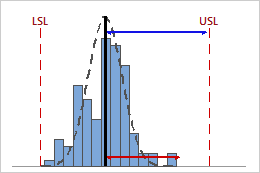
High CPU
In this example, the distance from the process mean to the upper specification limit (USL) is considerably greater than the one-sided process spread. Therefore, CPU is high (2.04), and the potential capability of the process is good in relation to its upper specification limit.
-
Compare CPU with a benchmark value to assess the potential capability of your process. Many industries use a benchmark value of 1.33. If CPU is lower than your benchmark, consider ways to improve your process, such as reducing its variation or shifting its location.
-
If you have both lower and upper specification limits, compare CPL with CPU. If CPL does not approximately equal CPU, the process is not centered.
CPL = 0.92, CPU = 4.37
When CPL < CPU, the process is more likely to produce defective units that violate the lower specification limit.
CPL = 4.37, CPU = 0.92
When CPU < CPL, the process is more likely to produce defective units that violate the upper specification limit.
Cpk
- The distance from the process mean to the closest specification limit (USL or LSL)
- The one-sided spread of the process (the 3-σ variation) based on the within-subgroup standard deviation
Interpretation
Use Cpk to evaluate the potential capability of your process based on both the process location and the process spread. Potential capability indicates the capability that could be achieved if process shifts and drifts were eliminated.
Generally, higher Cpk values indicate a more capable process. Lower Cpk values indicate that your process may need improvement.
Low Cpk
In this example, the distance from the process mean to the nearest specification limit (USL) is less than the one-sided process spread. Therefore, Cpk is low (0.80), and the potential capability of the process is poor.
High Cpk
In this example, the distance from the process mean to the nearest specification limit (LSL) is greater than the one-sided process spread. Therefore, Cpk is high (1.64), and the potential capability of the process is good.
You can compare Cpk with other values to get more information about the capability of your process.
-
Compare Cpk with a benchmark that represents the minimum value that is acceptable for your process. Many industries use a benchmark value of 1.33. If Cpk is lower than your benchmark, consider ways to improve your process, such as reducing its variation or shifting its location.
-
Compare Cp and Cpk. If Cp and Cpk are approximately equal, then the process is centered between the specification limits. If Cp and Cpk differ, then the process is not centered.
-
Compare Ppk and Cpk. When a process is in statistical control, Ppk and Cpk are approximately equal. The difference between Ppk and Cpk represents the improvement in process capability that you could expect if shifts and drifts in the process were eliminated.
Caution
The Cpk index represents only one side of the process curve, and does not measure how the process performs on the other side of the process curve.
For example, the following graphs display two processes with identical Cpk values. However, one process violates both specification limits, and the other process only violates the upper specification limit.
Cpk = min {CPL = 4.58, CPU = 0.93} = 0.93
Cpk = CPL = CPU = 0.93
If your process has nonconforming parts that fall on both sides of the specification limits, consider using other indices to more fully assess process capability.
Confidence interval (CI), Lower bound (LB), Upper bound (UB) for capability indices
The confidence interval is a range of likely values for a capability index. The confidence interval is defined by a lower bound and an upper bound. The bounds are calculated by determining a margin of error for the sample estimate. The lower confidence bound defines a value that the capability index is likely to be greater than. The upper confidence bound defines a value that the capability index is likely to be less than.
Note
To display confidence intervals, you must click Options and select Include confidence intervals when you perform the capability analysis. Minitab displays a confidence interval or a confidence bound for Cp, Pp, Cpk, Ppk, Cpm, and Z.bench.
Interpretation
Because samples of data are random, different samples collected from your process are unlikely to yield identical estimates of a capability index. To calculate the actual value of the capability index for your process, you would need to analyze data for all the items that the process produces, which is not feasible. Instead, you can use a confidence interval to determine a range of likely values for the capability index.
At a 95% confidence level, you can be 95% confident that the actual value of the capability index is contained within the confidence interval. That is, if you collect 100 random samples from your process, you can expect approximately 95 of the samples to produce intervals that contain the actual value of the capability index.
The confidence interval helps you to assess the practical significance of your sample estimate. When possible, compare the confidence bounds with a benchmark value that is based on process knowledge or industry standards.
For example, a company uses a minimum benchmark value of 1.33 for Ppk to define a capable process. Using capability analysis, they obtain a Ppk estimate of 1.46, which suggests that the process is capable. To further assess this estimate, they display a 95% lower confidence bound for Ppk. If the 95% lower confidence bound is greater than 1.33, they can be extremely confident that their process is capable, even when taking into account the variability from random sampling that affects the estimate.
Z.LSL for Potential (Within) Capability
Z.LSL (within) is the number of standard deviations between the process mean and the lower specification limit (LSL). It is calculated based on the potential (within) process performance, using the within-subgroup standard deviation.
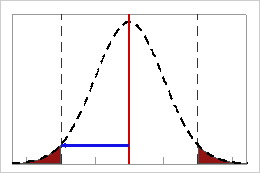
In this example, the within-subgroup standard deviation is represented by the tick marks on the horizontal scale. The distance between the process mean and the lower specification limit is 2 standard deviations, so the value of Z.LSL (within) is 2.
Note
To display Z.bench measures, you must click Options and change the default output from capability statistics to benchmark Z's when you perform the capability analysis.
Interpretation
Use Z.LSL (within) to evaluate the potential sigma capability of your process relative to the lower specification limit. Potential capability indicates the capability that could be achieved if process shifts and drifts were eliminated.
Generally, higher Z.LSL values indicate that the process is capable at the lower tail of the distribution. Lower values indicate that your process may need improvement. When possible, compare Z.LSL (within) with a benchmark value based on process knowledge or industry standards. If Z.LSL is less than your benchmark, consider ways to improve your process.
Z.USL for Potential (Within) Capability
Z.USL (within) is the number of standard deviations between the process mean and the upper specification limit (USL). It is calculated based on the potential (within) process performance, using the within-subgroup standard deviation.
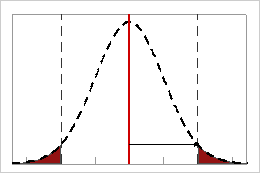
In this example, the within-subgroup standard deviation is represented by the tick marks on the horizontal scale. The distance between the process mean and the upper specification limit is 2 standard deviations, so the value of Z.USL (within) is 2.
Note
To display Z.bench measures, you must click Options and change the default output from capability statistics to benchmark Z's when you perform the capability analysis.
Interpretation
Use Z.USL (within) to evaluate the potential sigma capability of your process relative to the upper specification limit. Potential capability indicates the capability that could be achieved if process shifts and drifts were eliminated.
Generally, higher Z.USL values indicate that the process is capable at the upper tail of the distribution. Lower values indicate that your process may need improvement. When possible, compare Z.USL (within) with a benchmark value based on process knowledge or industry standards. If Z.USL is less than your benchmark, consider ways to improve your process.
Z.Bench for Potential (Within) Capability
Z.bench (within) is the percentile on a standard normal distribution that translates the estimated probability of defects in the process to an upper tail probability. It is calculated based on the potential (within) process performance, using the within-subgroup standard deviation.
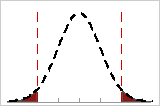
The defects for the process fall on both sides of the specification limits. The within-subgroup standard deviations are shown by the tick marks.
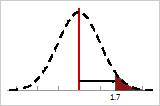
If you put all the defects on the right tail of the distribution, and then measure the number of within-subgroup standard deviations from the center (vertical line) to the point that defines the total defects, you obtain the Z-bench (within) value.
Note
To display Z.bench measures, you must click Options and change the default output from capability statistics to benchmark Z's when you perform the capability analysis.
Interpretation
Use Z.Bench (within) to evaluate the potential sigma capability of your process. Potential capability indicates the capability that could be achieved if process shifts and drifts were eliminated.
Generally, higher Z.bench (within) values indicate that the process is more capable. Lower values indicate that your process may need improvement. When possible, compare Z.bench (within) with a benchmark value based on process knowledge or industry standards. If Z.bench (within) is less than your benchmark, consider ways to improve your process.
Compare Z.Bench (within) and Z.Bench (overall). When a process is in statistical control, Z.Bench (within) and Z.Bench (overall) are approximately equal. The difference between the two values represents the improvement in process capability that you could expect if the process were brought into control. Zbench (Within) is sometimes referred to as Z.Bench Short-Term (ST).
CCpk
- The process target, if one is specified, or
- The center of the specification spread, if you provide both the upper and lower specification limits, or
- The process average, otherwise
Compare your CCpk value to a benchmark to determine whether to improve your process; many industries use a benchmark value of 1.33.
For example, the process below has an unacceptable CCpk value; it has such a wide spread that even when the mean is on target, the process violates both specification limits.
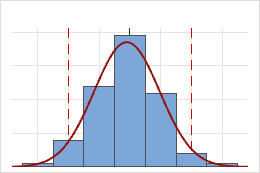
CCpk = 0.90
Note
If you provide no target and only one specification limit, CCpk is equal to Cpk.